正则表达式就像是一把精密的文字钥匙,能够帮我们精准地匹配和处理文本数据。在Java编程中,正则表达式的应用无处不在,从简单的表单验证到复杂的数据提取,都离不开它的帮助。
1.1 正则表达式基本语法和元字符详解
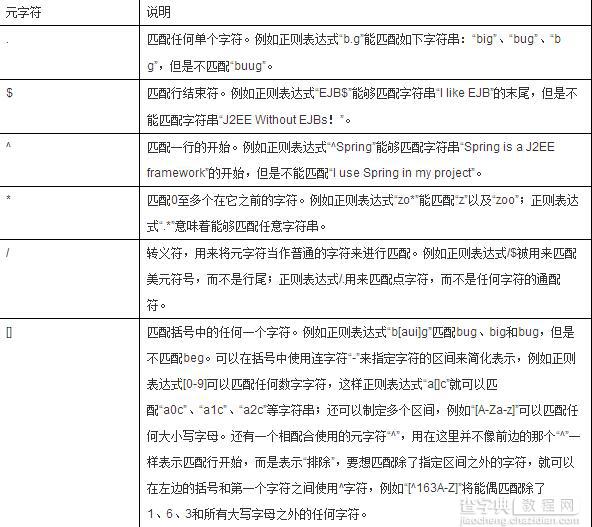
正则表达式的核心在于元字符——这些特殊符号赋予了普通文本强大的匹配能力。比如点号.可以匹配任意单个字符,星号*表示前面的元素可以出现零次或多次。
字符类用方括号[]定义匹配范围,[a-z]匹配任意小写字母,[0-9]匹配数字。预定义字符类让编写更简洁,\d等价于[0-9],\w匹配单词字符。
量词控制匹配次数,{n}表示精确匹配n次,{n,}至少n次,{n,m}匹配n到m次。边界匹配符^和$分别匹配行首和行尾。
我记得第一次使用\bword\b来匹配完整单词时,那种精准定位的感觉确实很奇妙。元字符的组合使用就像搭积木,简单的规则能构建出复杂的匹配模式。
1.2 Java中Pattern和Matcher类的使用方法
Java通过java.util.regex包提供正则表达式支持,核心就是Pattern和Matcher这两个类。Pattern负责编译正则表达式,Matcher负责执行匹配操作。
创建Pattern对象需要调用Pattern.compile()方法,这个步骤会将字符串形式的正则表达式编译成内部格式。编译后的Pattern对象是线程安全的,可以重复使用。
Matcher对象通过Pattern的matcher()方法创建,它提供丰富的匹配方法:matches()要求整个字符串完全匹配,find()在字符串中查找下一个匹配,lookingAt()从开头开始匹配。
分组功能特别实用,圆括号()不仅改变优先级,还创建捕获组。通过group(int group)方法可以提取特定分组的内容,groupCount()返回分组数量。
替换操作也很方便,replaceAll()和replaceFirst()能快速完成文本替换。我曾在处理用户输入时大量使用这些方法,确实大大提升了代码的简洁性。
1.3 常用正则表达式模式示例
实际开发中有些模式会反复出现,掌握这些常用模式能节省很多时间。数字匹配可以用^\d+$,整数验证用^-?\d+$,浮点数用^-?\d+\.?\d*$。
邮箱的简单验证可以用^\w+@\w+\.\w+$,中文匹配用[\u4e00-\u9fa5],URL匹配相对复杂些,需要处理协议、域名和路径。

日期格式验证很常见,^\d{4}-\d{2}-\d{2}$匹配YYYY-MM-DD格式。手机号验证在中国通常是^1[3-9]\d{9}$,这个模式考虑了号段的变化。
空白行匹配用^\s*$,HTML标签匹配用<[^>]+>。实际使用时,这些基础模式往往需要根据具体需求进行调整。
正则表达式的学习需要循序渐进,从简单模式开始练习,逐步掌握更复杂的组合技巧。多写多练是掌握这门技能的唯一途径。 Pattern emailPattern = Pattern.compile("^[\w.%+-]+@[\w.-]+\.[a-zA-Z]{2,}$", Pattern.CASE_INSENSITIVE); Matcher matcher = emailPattern.matcher(inputEmail); if(matcher.matches()) {
// 验证通过的处理逻辑
}
// 贪婪匹配 - 会匹配过多内容 Pattern greedy = Pattern.compile("
// 非贪婪匹配 - 按预期匹配单个标签对 Pattern reluctant = Pattern.compile("
