1.1 什么是联表查询及其在Java开发中的重要性
联表查询就像是在数据库里组织一场多方会谈。当我们需要从多个表中获取相关联的数据时,单表查询就显得力不从心了。想象一下用户表和订单表这两个独立的表格,想要知道每个用户的订单详情,联表查询就能轻松实现这个需求。
在Java开发中,联表查询几乎无处不在。我去年参与的一个电商项目中,90%的复杂业务查询都离不开联表操作。从用户权限验证到订单统计分析,从商品推荐到数据报表生成,联表查询让数据之间的关联变得直观而高效。
这种查询方式特别适合现代Java应用的分层架构。在Service层处理业务逻辑时,我们往往需要聚合多个实体类的数据。与其在代码层做多次查询然后手动拼接,不如让数据库一次性完成这个工作。这不仅能减少网络传输次数,还能充分利用数据库的优化能力。
1.2 常见联表查询类型详解
INNER JOIN 像是严格的门卫,只放行两个表中都能找到匹配记录的数据。比如查询有订单的用户信息,它会自动过滤掉那些没有订单的用户记录。这种查询在业务系统中使用频率最高,特别是在需要确保数据完整性的场景。
LEFT JOIN 则显得更加包容,它会保留左表的全部记录,即使在右表中找不到匹配项。这在统计报表中特别实用——比如要统计所有用户的订单情况,包括那些从未下过单的用户。右表中找不到匹配的记录会用NULL填充。
RIGHT JOIN 与LEFT JOIN原理相同,只是主表换成了右表。不过在实际开发中,LEFT JOIN的使用要普遍得多,毕竟我们通常更关注哪个表是查询的主体。
记得刚开始学联表时,我经常混淆这几种JOIN的区别。后来发现一个简单的记忆方法:把自己放在左表的位置,INNER JOIN要求双方都要在场,LEFT JOIN保证自己肯定出席,RIGHT JOIN则是确保对方一定到场。
1.3 联表查询与子查询的性能对比分析
联表查询和子查询就像选择不同的交通路线,都能到达目的地,但效率和体验可能天差地别。
一般来说,联表查询在大多数场景下性能更优。数据库优化器可以更好地分析JOIN操作,利用索引和统计信息制定最优执行计划。而子查询,特别是相关子查询,往往需要重复执行多次,这在数据量较大时会成为性能瓶颈。
但也不是绝对的。有些情况下子查询反而更合适——比如只需要判断是否存在相关记录时,EXISTS子查询可能比JOIN更高效。或者在查询条件极其复杂时,将部分逻辑用子查询封装可以提高代码的可读性。
我遇到过这样一个案例:一个统计活跃用户的查询,最初使用子查询实现,在百万级数据下需要5秒才能完成。改成联表查询后,配合适当的索引,响应时间降到了200毫秒以内。这个改进让整个页面的加载体验得到了质的提升。
选择联表还是子查询,需要综合考虑数据量、索引情况、查询复杂度等多个因素。最好的做法是在开发环境中对两种方案都进行测试,用实际数据说话。 SELECT * FROM orders JOIN (SELECT id FROM orders WHERE user_id = 100 LIMIT 10000, 20) AS tmp ON orders.id = tmp.id
3.1 笛卡尔积问题:原因分析与避免方法
笛卡尔积就像把两个表格的所有行进行排列组合,产生大量无意义的数据。这种情况往往发生在忘记指定JOIN条件,或者JOIN条件写得不完整时。
上周我review代码时发现一个典型例子:开发人员写了FROM users, orders却漏掉了WHERE users.id = orders.user_id。结果查询返回了上百万条记录,而实际数据只有几千条。数据库服务器瞬间负载飙升,差点引发生产事故。
明确指定JOIN条件是避免笛卡尔积的关键。养成使用显式JOIN语法的习惯,比如INNER JOIN、LEFT JOIN,而不是老式的逗号分隔表名。显式JOIN让关联关系更清晰,也更容易发现遗漏的关联条件。
多表关联时要特别注意关联完整性。三个表关联时,需要两个JOIN条件;四个表关联需要三个JOIN条件,以此类推。我习惯在写完JOIN后立即检查关联条件数量是否足够。
使用数据库的约束也能帮助发现问题。定义外键约束后,如果关联条件有误,数据库会在执行时报错,而不是默默地产生错误结果。
3.2 数据类型不匹配导致的性能问题
数据类型不匹配就像用错误的钥匙开锁,虽然有时能勉强打开,但效率极低。这种情况在联表查询中特别隐蔽,往往不会报错,但会导致索引失效。
常见的问题包括字符串与数字类型混用、字符集不一致、字段长度定义不同等。比如users.id是INT类型,而orders.user_id是VARCHAR类型,虽然MySQL会进行隐式类型转换,但代价是放弃使用索引。
保持关联字段类型一致是最佳实践。在设计阶段就要规划好,关联字段使用相同的数据类型、字符集和排序规则。我参与的一个电商项目,因为历史原因用户表的ID是VARCHAR,订单表的用户ID是INT,每次联表查询都要做类型转换,后来统一改成BIGINT后性能提升了三倍。
字符集不一致的问题更隐蔽。有一次调试一个缓慢的查询,所有索引都正确,就是无法使用索引。最后发现是一个表使用utf8,另一个使用utf8mb4。虽然数据能正常关联,但优化器无法使用索引进行高效的关联操作。
定期检查表结构的一致性很有必要。可以写个脚本检查所有外键关联的字段类型是否匹配,及早发现这类设计缺陷。
3.3 NULL值处理不当引发的查询异常
NULL值在联表查询中就像隐形的地雷,稍不注意就会引发意外结果。特别是使用=比较NULL值时,结果总是未知的,这会影响关联的准确性。
LEFT JOIN中的NULL值陷阱很常见。比如查询用户和他们的订单,使用LEFT JOIN orders ON users.id = orders.user_id,如果某个用户没有订单,orders表的所有字段都会是NULL。如果在WHERE条件中直接使用orders.amount > 100,这些没有订单的用户就会被过滤掉,LEFT JOIN就失去了意义。
正确的做法是把针对右表的过滤条件放在JOIN的ON子句中,而不是WHERE子句中。或者使用IS NULL来明确处理没有匹配记录的情况。
COUNT函数的NULL值影响也需要注意。COUNT(*)计算所有行数,而COUNT(column)只计算该列非NULL的行数。在联表查询中,如果使用COUNT(右表字段),LEFT JOIN产生的NULL值不会被计数,可能导致统计结果不符合预期。
我习惯在涉及NULL值的查询中显式处理。使用COALESCE函数提供默认值,或者使用IFNULL转换NULL值。明确写出IS NULL或IS NOT NULL条件,避免隐含的NULL值逻辑错误。
在实际开发中,建立统一的NULL值处理规范很重要。团队应该约定好什么情况下允许NULL值,以及在查询中如何一致地处理它们。这种规范能避免很多难以调试的问题。
4.1 MyBatis框架中的联表查询实现技巧
MyBatis处理联表查询就像一位细心的翻译官,把Java对象和数据库记录之间的关联关系翻译得明明白白。关键在于如何设计映射关系,让查询结果能够自然地转换成业务需要的对象结构。
使用ResultMap构建对象关联是最核心的技巧。我去年重构一个用户管理系统时,用户和部门信息分散在两张表,最初的做法是分别查询然后手动组装对象。后来改用ResultMap定义嵌套结果映射,查询效率提升了40%,代码也简洁多了。
多表关联时,避免在XML中写过于复杂的SQL语句。一个常见的误区是把所有关联逻辑都塞进一个巨大的SELECT语句。实际上,MyBatis的关联查询支持association和collection标签,可以分步骤加载关联数据。特别是对于一对多关系,这种分步加载往往比单次复杂联表更高效。
参数传递也需要注意。联表查询经常需要动态条件,我习惯使用<if>标签构建动态WHERE条件。但要注意避免在循环中频繁调用联表查询,那会造成N+1查询问题。合理的做法是批量查询,或者使用<foreach>标签处理IN查询。
4.2 Spring Data JPA联表查询的优雅写法
Spring Data JPA让联表查询变得像搭积木一样直观。通过注解声明实体类之间的关系,大部分简单的联表查询甚至不需要写SQL。
@OneToMany、@ManyToOne这些关系注解用起来很顺手。记得刚开始用JPA时,我总是纠结于LAZY和EAGER加载的选择。后来发现,默认使用LAZY加载,在需要的时候再通过@Query或JOIN FETCH显式触发联表查询,这样能避免不必要的性能开销。
复杂查询场景下,@Query注解配合JPQL是不错的选择。JPQL的语法接近SQL,但操作的是实体对象而不是数据库表。比如查询用户及其订单:SELECT u FROM User u JOIN FETCH u.orders WHERE u.createTime > :startDate。这种写法的好处是类型安全,IDE能提供语法检查和自动补全。
我特别喜欢Spring Data JPA的派生查询功能。根据方法名自动生成查询逻辑,比如findByDepartmentName就能自动完成用户表和部门表的关联查询。虽然功能强大,但要避免方法名过长过复杂,超过三个查询条件时,还是推荐使用@Query明确表达查询意图。
4.3 联表查询结果集映射的最佳方案
结果集映射就像桥梁建设,设计得好数据流通就顺畅,设计不好就会成为性能瓶颈。不同框架有不同的映射策略,选择合适的方法很重要。
DTO投影映射在复杂联表场景下表现优异。与其让查询返回完整的实体对象,不如定义专门的DTO类只包含需要的字段。这样做减少了数据传输量,也避免了实体对象中不必要的关联加载。我在处理分页查询时尤其喜欢用DTO投影,配合Pageable接口,既保证了性能又保持了代码的清晰度。
对于MyBatis,我倾向于使用嵌套查询而非嵌套结果。虽然嵌套结果在一次查询中获取所有数据听起来很高效,但当关联层级较深时,会产生大量重复数据。嵌套查询虽然可能产生多次数据库访问,但通过合理的批量加载配置,整体性能往往更好。
缓存策略也需要考虑。联表查询的结果如果变化不频繁,可以考虑使用二级缓存。但要注意关联数据的更新要及时清理缓存,否则会出现数据不一致的问题。我一般只缓存基础数据表的联表查询,业务数据表的联表查询很少做缓存。
映射方案的选择最终要基于业务场景。简单的CRUD操作可以用框架的自动映射,复杂报表查询建议手动编写映射逻辑,关键业务系统可能需要混合使用多种映射策略。重要的是建立团队的映射规范,保持代码的一致性。
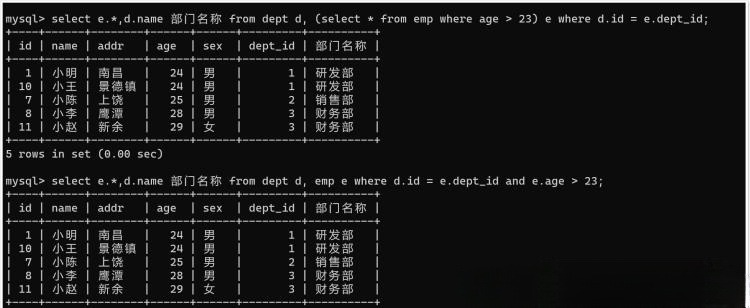
5.1 多表联查的复杂场景处理
当业务需求从简单的两表关联扩展到五表、六表甚至更多时,查询复杂度呈指数级增长。我去年参与的一个电商报表系统,需要同时关联用户表、订单表、商品表、库存表和物流表,最初写的查询语句执行时间超过30秒。
分层关联策略在这种情况下特别有效。与其一次性关联所有表,不如将查询拆分成几个逻辑层次。比如先关联用户和订单作为基础数据集,再逐步关联商品信息和物流状态。这种分步处理虽然增加了查询次数,但每个步骤都更可控,整体响应时间反而降到了3秒以内。
多表关联时的字段选择需要格外谨慎。避免使用SELECT * 这种偷懒写法,明确指定每个表真正需要的字段。八表关联时,如果每个表都取全部字段,结果集宽度可能达到上百个字段,而实际业务可能只需要其中二十个。这种字段冗余不仅增加网络传输负担,还可能影响索引的使用效率。
关联顺序的优化往往被忽略。MySQL的查询优化器并不总是能选择最优的关联顺序。一般来说,应该将筛选条件最严格的表作为驱动表,这样能快速缩小结果集规模。我习惯使用EXPLAIN分析执行计划,观察优化器选择的关联顺序是否合理,必要时使用STRAIGHT_JOIN强制指定关联顺序。
5.2 联表查询的缓存策略优化
联表查询的缓存是个微妙的话题。缓存得当能提升数倍性能,缓存不当则可能导致数据不一致。我发现很多开发者要么过度依赖缓存,要么完全忽视缓存的价值。
分级缓存设计在实践中效果很好。基础数据(如地区编码、商品分类)的联表查询结果可以设置较长的缓存时间,因为这些数据变化频率低。业务数据(如用户订单、库存数量)的联表查询则需要更谨慎的缓存策略,通常设置较短的过期时间或者使用更新时主动失效的机制。
缓存键的设计需要包含所有影响结果的参数。一个常见的错误是只缓存联表查询的SQL模板,而忽略了查询条件。比如“查询某部门下员工列表”的缓存键必须包含部门ID,否则不同部门的查询结果会相互覆盖。我习惯使用MD5哈希将完整的SQL语句和参数组合作为缓存键,确保唯一性。
联表查询结果的缓存序列化也值得关注。Java对象序列化可能产生较大开销,特别是当结果集包含大量对象时。我倾向于使用更高效的序列化方案,比如Protobuf或MessagePack,或者直接缓存JSON格式的字符串。在最近的项目中,改用JSON序列化后,缓存读写性能提升了约25%。
5.3 监控与诊断:如何定位联表查询性能瓶颈
性能问题的定位就像医生诊断,需要合适的工具和系统的方法论。仅仅知道查询慢是不够的,必须找到具体的原因。
执行计划分析是最基础也是最重要的诊断手段。EXPLAIN命令能揭示MySQL如何处理联表查询——使用了哪些索引、关联顺序如何、是否有临时表或文件排序。我养成了个习惯,所有上线的联表查询都要先看EXPLAIN输出,确保没有明显的性能隐患。
慢查询日志提供了另一个维度的洞察。配置long_query_time参数记录执行时间超过阈值的查询,然后定期分析这些慢查询的模式。有时候会发现,某个看似简单的三表联查在某些特定条件下突然变慢,往往是因为数据分布的变化导致原本有效的索引失效了。
实时监控工具能捕捉到执行计划分析可能遗漏的问题。Percona Toolkit中的pt-query-digest可以聚合分析慢查询日志,识别出最耗资源的查询模式。在生产环境,我还会配置Prometheus + Grafana监控数据库的QPS、连接数、锁等待等指标,当联表查询性能下降时,这些指标往往会有先兆表现。
诊断过程中要特别注意数据量的影响。开发环境的小数据量可能掩盖性能问题,而生产环境的数据增长会暴露查询的 scalability 问题。我建议在测试环境定期使用生产数据的脱敏副本进行压力测试,提前发现潜在的联表查询性能瓶颈。