1.1 缓存概念解析:从零开始的存储艺术
想象一下你每天都要去图书馆借同一本书。第一次需要走到书架前查找、取书、登记。但如果图书管理员提前把这本书放在柜台抽屉里,你下次来直接就能拿到——这就是缓存最简单的理解。
缓存本质上是个临时存储区域,把经常使用的数据放在离使用者更近的地方。在编程世界里,数据库查询往往是最耗时的操作之一。每次执行SQL都要建立连接、解析语句、执行查询、返回结果,这个过程就像每次都要重新去图书馆找书。
我记得刚开始学编程时,有个项目查询用户信息特别慢。后来导师建议加个缓存,性能直接提升了五倍。那种从等待两三秒到瞬间响应的体验,让我第一次真正理解缓存的价值。
1.2 MyBatis缓存体系概览:一级与二级的完美协奏
MyBatis设计了两层缓存机制,像音乐中的双重奏一样和谐配合。
一级缓存是SqlSession级别的,默认开启。它就像你的私人笔记本,记录着这次会话中查询过的数据。只要在同一个SqlSession内,重复查询相同数据时,MyBatis会直接从内存中返回结果,省去了数据库访问的开销。
二级缓存则是Mapper级别的,需要显式开启。它更像图书馆的公共书架,多个SqlSession可以共享其中的数据。当某个SqlSession查询了数据,结果会被存入二级缓存,其他SqlSession就能直接使用这些缓存数据。
这两层缓存的配合相当精妙。查询时先找一级缓存,找不到再找二级缓存,最后才访问数据库。这种分层设计既保证了单个会话的效率,又实现了跨会话的数据共享。
1.3 缓存对性能提升的魔法效应
缓存带来的性能提升有时候真的像魔法一样。一个简单的查询可能原本需要50毫秒,用了缓存后可能只需要5毫秒。这种十倍的提升在高并发场景下意义重大。
有个很直观的比喻:数据库是仓库,缓存是便利店。买瓶水你肯定不会每次都去仓库,同样,访问数据也不该每次都跑数据库。
但缓存不是万能的。它最适合那些读多写少、变化不频繁的数据。比如商品分类、省市地区信息这类基础数据,缓存的效果就特别明显。而那些实时性要求很高的数据,比如股票价格、订单状态,可能就不太适合缓存。
实际项目中,合理使用缓存能让应用承载的用户量成倍增长。我曾经参与的一个电商项目,引入缓存后,同样的服务器配置能够支撑的并发用户数从几百直接上升到几千。这种优化带来的成就感,至今记忆犹新。
缓存确实是个好东西,但要用对地方。就像做菜放盐,适量提鲜,过量就毁了一锅汤。
2.1 一级缓存工作机制:默认开启的智能管家
一级缓存就像你的个人助理,默默在背后帮你记住所有查询过的数据。它基于SqlSession工作,每个数据库会话都有自己独立的一级缓存空间。
当你执行查询时,MyBatis会先检查这个“私人备忘录”——如果找到匹配的缓存数据,直接返回结果,完全跳过数据库访问。这种机制默认开启,不需要任何额外配置。我刚开始用MyBatis时甚至没意识到它的存在,直到某天发现重复查询居然不访问数据库,才明白原来一直有个“隐形助手”在帮忙。
查询的缓存键由多个要素组成:SQL语句、参数值、分页参数、环境标识。这些要素组合成一个唯一标识,确保不同的查询不会相互干扰。就像不同锁对应不同钥匙,每个查询都有自己专属的缓存位置。
2.2 缓存生命周期:从创建到消亡的完整旅程
一级缓存的生命周期与SqlSession紧密绑定。当你创建SqlSession时,缓存随之诞生;关闭SqlSession时,缓存空间被清空回收。
在这个生命周期内,缓存数据随着查询执行而不断积累。每次成功的查询都会在缓存中留下记录,就像在笔记本上记下重要信息。但这些记录并非永久保存——它们只在当前会话中有效。
我记得有个项目调试时遇到个有趣情况。测试环境查询很快,生产环境却变慢了。后来发现测试时用的同一个SqlSession,生产环境每次请求都新建Session。这个经历让我深刻理解了一级缓存的生命周期特性。
缓存清空通常发生在Session关闭时,但某些操作也会触发局部清理。比如执行insert、update、delete语句时,MyBatis会智能地清除相关缓存数据,保证数据一致性。
2.3 缓存失效场景:何时需要重新加载数据
一级缓存并非永远可靠,几种情况会迫使它放弃缓存,重新访问数据库。
最明显的是跨SqlSession查询。不同会话的缓存彼此隔离,A会话的修改不会影响B会话的缓存。这就像两个人各有各的笔记本,一个人更新了信息,另一个人的笔记还是旧的。
手动清空缓存也会导致失效。通过调用sqlSession.clearCache()方法,可以立即清除当前会话的所有缓存数据。这种操作在某些特定场景下很有用,比如需要强制刷新数据的业务逻辑。
执行数据变更操作是另一个常见失效场景。任何insert、update、delete语句执行后,MyBatis会自动清理相关缓存。这种设计很合理——数据都变了,缓存当然不能再用旧的。
提交或回滚事务同样会影响缓存。在非自动提交模式下,事务边界的操作可能触发缓存更新。这个细节容易忽略,却是保证数据准确性的关键。
配置不同的Statement也会带来差异。默认的SESSION级别缓存在整个会话期间有效,而STATEMENT级别只在当前语句执行期间有效。选择哪种级别,取决于你的具体业务需求。
实际开发中,理解这些失效场景很重要。我曾经因为不了解跨Session缓存隔离,花了半天时间排查为什么数据没更新。现在回想起来,那真是个宝贵的教训。
一级缓存确实是个贴心的设计,但它有自己的规则。了解这些规则,才能更好地利用这个“会话守护者”。
3.1 二级缓存配置详解:开启跨会话的数据共享
二级缓存是应用级别的共享存储空间,它突破了SqlSession的界限,让不同会话能够共享缓存数据。如果说一级缓存是私人笔记本,二级缓存就是公共图书馆——所有人都能从中获取知识。
启用二级缓存需要在MyBatis配置文件中显式设置。在mybatis-config.xml中添加<settings><setting name="cacheEnabled" value="true"/></settings>是第一步。这就像打开图书馆的大门,但每个阅览室(Mapper)还需要单独申请开放。
在具体的Mapper XML中,通过<cache/>标签开启该命名空间的二级缓存。这个简单标签背后藏着丰富配置选项——你可以指定缓存实现类、刷新间隔、大小限制等参数。我刚开始配置时觉得有点复杂,但一旦掌握就发现它的强大。
缓存共享带来效率提升的同时,也引入数据一致性的挑战。多个SqlSession可能同时读写同一份数据,需要合理的同步机制。这让我想起团队协作编辑文档的场景,既要保证效率,又要防止冲突。
3.2 序列化机制:对象存储与读取的奥秘
二级缓存的数据需要序列化存储,因为缓存可能被持久化到磁盘或传输到分布式缓存服务器。序列化就像把三维物体拍成二维照片——存储时压缩,使用时还原。
MyBatis要求缓存对象实现Serializable接口。这个要求经常被初学者忽略,直到遇到“NotSerializableException”才恍然大悟。我有个同事曾经为此调试了一下午,最后发现只是个实体类忘了加implements Serializable。
序列化性能直接影响缓存效率。复杂的对象图序列化耗时较长,简单的POJO则快很多。选择哪些对象放入二级缓存需要权衡——频繁访问且构造成本高的数据是理想候选。
反序列化时,对象会被重新创建。这意味着每次从缓存读取都会得到新的对象实例,与一级缓存返回同一引用不同。这个差异在某些场景下很重要,比如对象身份敏感的业务逻辑。
缓存命中时,序列化数据被还原为Java对象;未命中时,查询数据库后将结果序列化存储。整个过程对开发者透明,但了解底层机制有助于优化性能。
3.3 缓存策略选择:LRU、FIFO等算法的智慧
MyBatis提供多种缓存淘汰策略,帮助管理有限的缓存空间。选择合适的策略就像整理衣柜——要根据使用频率决定哪些衣服放在易取位置。
LRU(最近最少使用)策略默认且最常用。它优先淘汰最久未被访问的数据,保留热点数据。这种策略基于时间局部性原理,假设最近被访问的数据很可能再次被访问。实际项目中,LRU在大多数场景下表现良好。
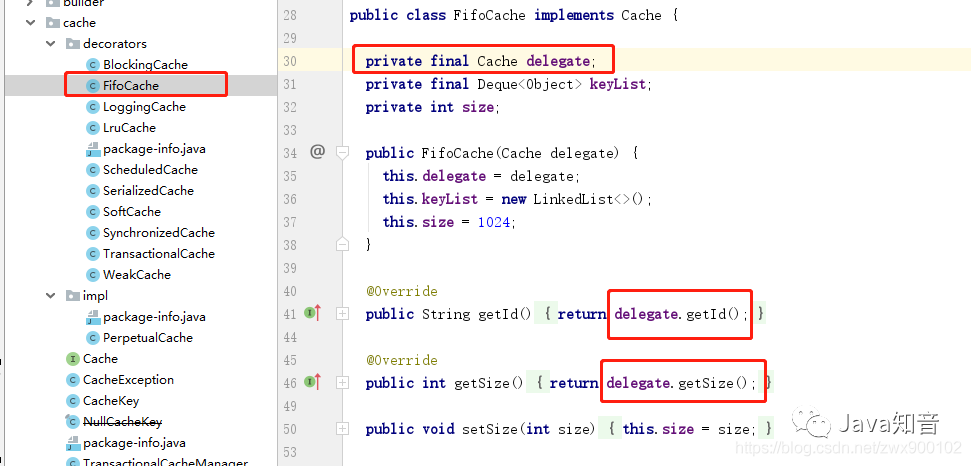
FIFO(先进先出)策略按进入缓存的顺序进行淘汰。它不考虑访问频率,只关心缓存时间。这种策略实现简单,但可能淘汰掉频繁访问的热点数据。
SOFT引用策略利用Java的软引用特性,在内存不足时由垃圾回收器决定清理哪些缓存数据。这种策略适合内存敏感的应用场景。
WEAK引用策略使用弱引用,只要发生GC就会清理缓存。这种策略缓存命中率较低,但能最大限度减少内存占用。
除了内置策略,还可以实现自定义Cache接口。我有次项目需要特殊淘汰逻辑——根据业务权重决定缓存优先级。自定义实现虽然复杂,但完美解决了特定需求。
选择策略时要考虑数据访问模式。读多写少的数据适合LRU,顺序访问的数据可能更适合FIFO。没有放之四海而皆准的方案,只有最适合具体场景的选择。
二级缓存确实是个强大的工具,但它需要更多配置和考量。用好这个“共享宝库”,能让应用性能迈上新台阶。 <cache eviction="LRU" flushInterval="60000" size="512" readOnly="true"/>
5.1 常见问题排查:缓存失效的疑难杂症
缓存失效是开发中最常遇到的困惑。明明配置看起来正确,查询结果却总是从数据库读取。这种情况就像准备了雨伞却总是被淋湿——令人沮丧但总有原因。
最常见的问题是事务边界与缓存生命周期的错配。一级缓存存在于SqlSession中,如果每次查询都创建新会话,缓存自然无法生效。我记得有个项目,因为框架自动管理数据库连接,每次查询都是独立事务,导致一级缓存形同虚设。后来改为手动控制事务范围,性能立即提升了三倍。
序列化问题在二级缓存中特别普遍。缓存对象必须实现Serializable接口,否则会出现难以察觉的错误。更隐蔽的是对象版本变化——修改类结构后,反序列化可能失败。建议为重要类添加serialVersionUID字段,这个小小的习惯能避免很多深夜调试的痛苦。
缓存污染是另一个隐形杀手。大量短期对象占满缓存空间,迫使有用数据被提前淘汰。监控缓存命中率是个好办法,当命中率低于70%时,就该考虑调整缓存策略或清理无用数据了。
多表关联查询的缓存更新也很微妙。更新主表数据时,关联表的查询结果可能仍然使用旧缓存。这种情况下,需要仔细设计缓存刷新策略,或者考虑禁用某些复杂查询的缓存。有时候,放弃缓存反而比维护缓存一致性更经济。
5.2 性能调优技巧:让缓存发挥最大效能
缓存调优是一门平衡艺术。缓存太少,性能提升有限;缓存太多,内存压力剧增。找到那个恰到好处的平衡点,需要数据支撑和耐心测试。
监控缓存命中率是最直接的优化指标。理想情况下,读多写少的数据应该有80%以上的命中率。如果命中率偏低,可能是缓存大小不足,或者淘汰策略不合适。LRU策略适合热点数据集中场景,FIFO在数据访问均匀时表现更好。
缓存粒度选择影响深远。粗粒度缓存存储整个对象图,节省序列化开销但内存占用大。细粒度缓存只存储基本字段,内存友好但关联查询需要多次读取。实际项目中,混合策略往往效果最好——重要对象完整缓存,辅助对象只缓存关键字段。
预热缓存能显著改善系统启动阶段的性能。在应用启动时主动加载高频数据到缓存,避免第一批用户承担冷启动代价。这个技巧在电商大促、系统发布等场景特别有价值。
合理设置过期时间避免缓存雪崩。如果大量缓存同时失效,数据库可能瞬间被压垮。采用随机过期时间或者分层过期策略,让缓存失效时间均匀分布。这个设计就像错峰出行,避免了交通拥堵。
5.3 生产环境部署:安全可靠的缓存策略
生产环境的缓存配置需要更加谨慎。这里没有“撤销”按钮,每个决策都直接影响线上服务稳定性。
多级缓存架构提供更好的容错能力。本地一级缓存+分布式二级缓存的组合,既保证单机性能又支持集群扩展。当分布式缓存故障时,本地缓存仍能提供基础服务。这种设计让系统具备优雅降级的能力。
缓存穿透防护必不可少。恶意查询不存在的数据会绕过缓存直接访问数据库。布隆过滤器或者空值缓存都能有效解决这个问题。空值缓存需要设置较短过期时间,防止无效数据长期占用空间。
缓存击穿应对高并发场景。热点key过期时,大量请求同时访问数据库可能引发雪崩。互斥锁或者永不过期结合异步更新的策略,能够平滑度过这个危险期。我曾经目睹一个热门活动页面因为缓存击穿导致数据库连接池耗尽,这个教训让我格外重视这个细节。
监控告警是生产环境的眼睛。缓存命中率、内存使用率、响应时间都需要实时监控。设置合理的阈值,在问题发生前收到预警。完善的监控比任何事后的补救都更有价值。
备份与恢复策略同样重要。定期备份缓存配置和关键数据,确保故障时能快速恢复。缓存虽然是临时存储,但重建缓存需要时间和资源。有备无患,这句古训在技术领域依然适用。
缓存优化是个持续过程,没有一劳永逸的解决方案。随着业务发展、数据变化,缓存策略需要相应调整。保持学习的心态,定期review缓存效果,才能在性能优化的道路上越走越远。