1.1 传统分页与MyBatis分页对比
还记得十年前我做项目时,分页查询需要在SQL里写一大堆计算语句。每次翻页都要重新计算起始位置,代码里充斥着limit (page-1)*size, size这样的片段。那种方式虽然直接,但维护起来确实让人头疼。
传统分页最大的问题在于代码重复度高。每个需要分页的查询都要重复编写分页逻辑,业务逻辑与分页逻辑紧密耦合。修改分页方式时,需要改动所有相关查询语句。
MyBatis分页提供了更优雅的解决方案。它将分页逻辑抽象出来,通过拦截器或插件机制自动处理分页参数。开发人员只需要关注业务查询逻辑,分页的具体实现由框架完成。这种设计让代码更加清晰,也更容易维护。
我特别喜欢MyBatis分页的这种设计理念,它真正做到了关注点分离。
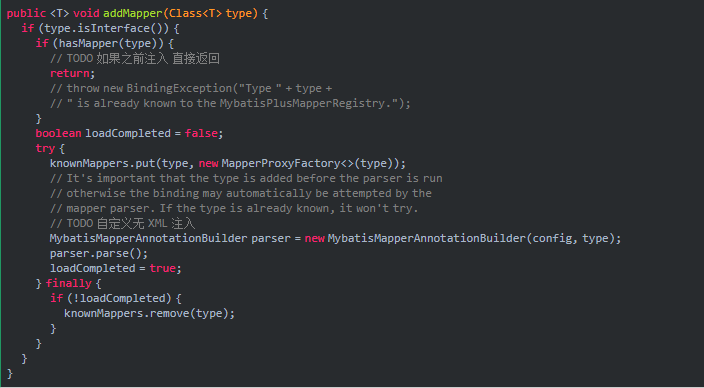
1.2 MyBatis分页核心组件介绍
MyBatis分页生态中有几个关键组件值得了解。首先是RowBounds,这是MyBatis自带的简单分页工具。它通过内存分页的方式工作,适合数据量不大的场景。
分页插件是另一个重要组成部分。比如流行的PageHelper,它通过拦截器机制在SQL执行前自动添加分页语句。这种方式的优势在于对原有代码侵入性小,使用起来非常方便。
分页参数对象也是核心组件之一。通常包含当前页码、每页大小、总记录数等基本信息。设计良好的分页参数对象能够为前后端数据交互提供统一的标准。
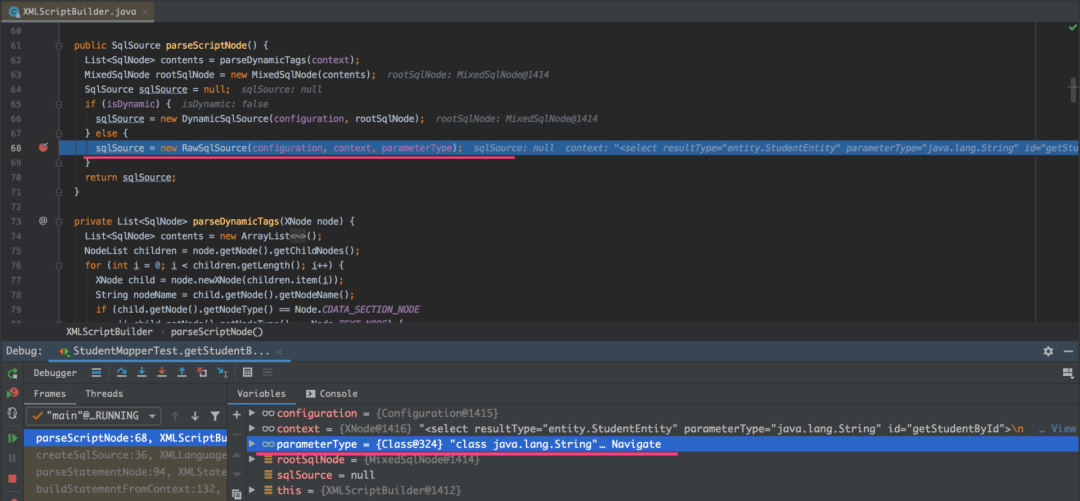
这些组件共同构成了MyBatis分页的基础架构,每个组件都有其特定的应用场景。
1.3 分页查询的基本原理分析
分页查询的本质是在数据库层面限制返回的数据量。当我们在页面上看到第5页的数据时,实际上执行的是limit 40, 10这样的SQL语句。这个简单的数字背后,是数据库引擎对全量数据的筛选过程。
从技术实现角度看,分页查询通常包含两个步骤:首先是获取满足条件的总记录数,然后是获取指定范围的数据记录。这两个步骤可能合并成一次查询,也可能分开执行,具体取决于实现方式。
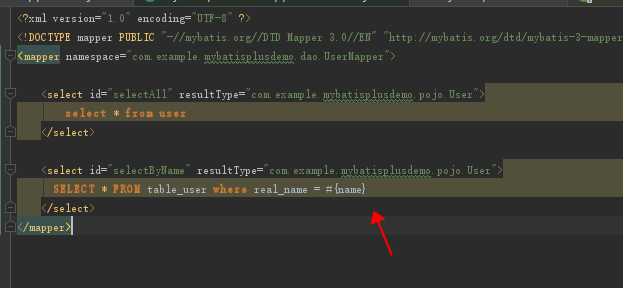
内存分页和数据库分页是两种不同的实现思路。内存分页先获取所有数据,然后在应用层进行分页处理。数据库分页则是在SQL层面完成数据筛选,只返回需要的部分数据。
在实际项目中,我一般会根据数据量的大小来选择合适的方案。数据量较小时,内存分页可能更简单;数据量大时,数据库分页的性能优势就体现出来了。
分页看似简单,但其中蕴含的设计思想确实值得我们深入思考。
List
@Service public class UserService {
public PageInfo<User> getUsersByPage(int pageNum, int pageSize) {
PageHelper.startPage(pageNum, pageSize);
List<User> users = userMapper.selectAllUsers();
return new PageInfo<>(users);
}
}
SELECT * FROM users LIMIT 20000, 20