1.1 关联查询的定义与作用
关联查询就像把分散在不同表格里的数据重新连接起来。想象一下图书馆的借阅系统——用户信息在一张表,借阅记录在另一张表。当你需要查看某个用户借了哪些书时,就需要把这两张表关联起来查询。
这种查询方式特别实用。它避免了在应用程序中手动拼接数据的繁琐,直接通过数据库层面完成数据关联。我刚开始接触MyBatis时,总是习惯先查主表数据,再循环查询关联表,结果代码写得又长又慢。后来发现关联查询能一次性解决这个问题,效率提升非常明显。
1.2 一对一、一对多、多对多关系解析
现实中的数据关系其实就这三种基本类型。
一对一关系很常见。比如用户和身份证信息,一个人对应一个身份证号码。在电商系统中,订单和物流信息通常也是一对一的关系。
一对多关系就像树枝和树叶。一个用户可以发表多篇文章,一个部门可以有多个员工。这种关系在实际开发中遇到的最多。记得我第一次做博客系统时,用户和文章就是典型的一对多关系。
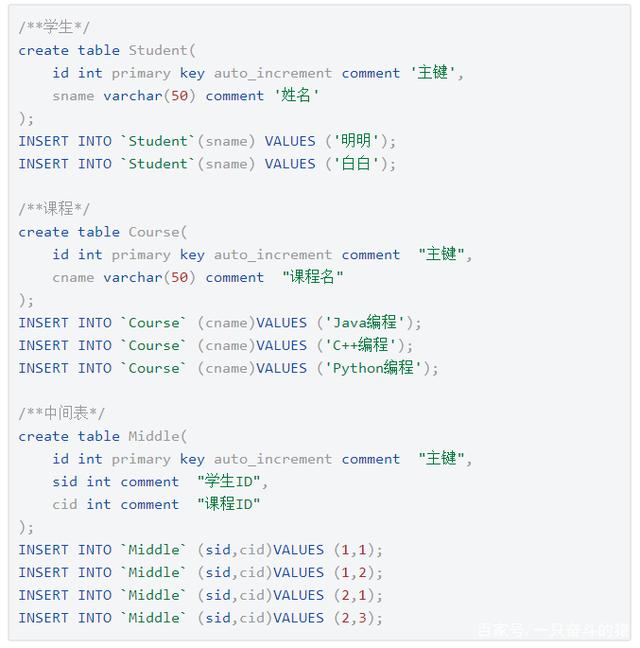
多对多需要中间表来帮忙。学生和课程的关系最典型——一个学生可以选多门课,一门课也可以被多个学生选。这种关系处理起来稍微复杂些,但理解了原理后其实很清晰。
1.3 MyBatis关联查询的核心配置元素
MyBatis提供了几个关键标签来处理关联关系。
<resultMap>是关联查询的蓝图,它定义了如何将数据库列映射到Java对象的属性。没有它,关联查询就像没有地图的旅行。
<association>处理一对一关系。它告诉MyBatis:“这个属性对应另一个对象,你需要按照我的指引去填充它。”
<collection>处理一对多关系。它说:“这里会有一组对象,你要把它们都找出来装进这个集合里。”
理解这些标签的配置方式很重要。刚开始可能会觉得配置有点繁琐,但熟悉之后会发现它们提供了很大的灵活性。每个标签都有自己独特的属性和使用场景,需要根据实际的数据关系来选择使用哪个。
关联查询让数据之间的关系变得清晰可见,就像用线把散落的珍珠串成完整的项链。
2.1 association标签的使用与配置
association标签是处理一对一关系的利器。它让两个独立的对象在查询结果中自然连接,就像给主对象找到了最匹配的伴侣。
配置association时,你需要关注几个关键属性。property指定了Java对象中的属性名,javaType定义了这个属性的类型,column则告诉MyBatis使用哪一列的值作为查询关联表的参数。我最近在做一个电商项目,订单和收货地址就是典型的一对一关系。通过association配置,查询订单时能自动带出完整的地址信息,省去了后续手动组装的麻烦。
association支持两种配置方式——嵌套查询和嵌套结果。嵌套查询更灵活,适合复杂条件;嵌套结果效率更高,适合简单关联。实际开发中我倾向于先用嵌套结果,遇到复杂场景再考虑嵌套查询。
2.2 collection标签的使用与配置
当需要处理“一对多”关系时,collection标签就派上用场了。它能把分散的多条记录聚合成一个完整的集合,就像把散落的珠子串成项链。
collection的配置与association类似,但有个重要区别——它使用ofType而不是javaType来指定集合中元素的类型。这个细节很容易被忽略,我第一次使用时就在这里栽了跟头。配置用户和文章的关系时,一个用户对应多篇文章,collection能把这些文章自动封装到List中,使用起来非常顺手。
collection也支持复杂的嵌套配置。你可以在collection内部继续使用association或其他collection,构建出多层级的对象树。这种能力在处理复杂业务对象时特别有用,虽然配置起来需要更多耐心。
2.3 嵌套查询与嵌套结果的区别
这两种方式的选择往往影响着查询性能和代码复杂度。
嵌套查询(Nested Query)分两步走:先查主表,再根据主表结果查关联表。它的SQL语句相对简单,但可能引发N+1查询问题。当主表有100条记录时,可能会产生101条SQL查询。
嵌套结果(Nested Results)通过表连接一次性获取所有数据,然后在内存中进行结果映射。它只需要一次数据库交互,效率更高,但SQL语句会比较复杂。我在性能敏感的场景下更倾向于使用嵌套结果,毕竟减少数据库访问次数往往能带来明显的性能提升。
选择哪种方式需要权衡。数据量小、关联复杂时用嵌套查询;追求性能、关联简单时用嵌套结果。没有绝对的好坏,只有适合与否。
2.4 延迟加载机制与配置
延迟加载是个很聪明的设计。它让关联数据“按需加载”,就像去图书馆不一定要把所有相关书籍都一次性借出来。
配置延迟加载需要在MyBatis全局设置中开启lazyLoadingEnabled。开启后,只有当真正访问关联对象时,MyBatis才会执行对应的查询语句。这个特性在大对象图中特别有用,能避免加载大量不需要的数据。
但延迟加载也有代价。它可能引发“延迟加载异常”,特别是在Web请求结束后才访问关联数据的情况。我遇到过这样的坑:在Service层获取了主对象,到了Controller层才访问关联属性,此时Session已经关闭,导致异常。解决方法是使用fetchType="eager"强制立即加载,或者在合适的时机完成所有数据加载。
合理使用延迟加载能显著提升性能,但需要根据业务场景精心设计加载策略。
3.1 用户与文章的一对多关系实现
在Java优学网中,每个用户可以发布多篇文章,这种一对多关系非常普遍。实现起来需要先在User类中定义一个List类型的articles属性,然后在Mapper映射文件中配置collection标签。
我去年参与过一个类似的知识分享平台开发,用户文章模块就是这样处理的。UserMapper.xml中的配置大致是这样的:使用collection标签,property设为"articles",ofType指定为Article类,通过column="user_id"建立关联。查询用户时,他发布的所有文章会自动封装到articles列表中。
这种配置让业务逻辑变得清晰。获取用户信息的同时,他的创作记录也一并呈现。前端展示用户主页时,不需要额外请求文章接口,数据完整性得到了保证。不过要注意数据量大的情况,用户如果发布了上千篇文章,一次性加载可能影响性能。
3.2 课程与分类的多对多关系处理
多对多关系需要中间表来维护,Java优学网的课程和分类就是典型例子。一门课程可能属于多个分类,一个分类下包含多门课程。
实现时需要三个实体类:Course、Category和中间表CourseCategory。在CourseMapper中配置collection标签时,需要通过中间表建立关联。我记得第一次配置多对多关系时,被复杂的SQL连接搞晕了,后来发现MyBatis的collection标签支持通过column传递多个参数,大大简化了配置。
实际查询时,MyBatis会执行连接查询,把课程对应的所有分类信息组装成集合。这种设计非常灵活,课程可以随时调整所属分类,不需要修改核心业务逻辑。数据展示时,一门课程的所有分类标签能同时显示,用户体验相当流畅。
3.3 复杂业务场景下的关联查询设计
真实项目中的关联查询往往比理论复杂得多。Java优学网有个特色功能——学习路径推荐,需要同时关联用户、课程、学习记录、评价等多个表。
这种情况下,简单的association或collection可能不够用。我倾向于采用分层映射的策略:先建立核心对象的关系,再逐步扩展关联。比如先配置用户与学习记录的一对多关系,在学习记录中再关联课程信息,课程中又关联分类和评价数据。
这种嵌套配置虽然复杂,但保持了代码的可维护性。每个映射关系职责单一,修改时影响范围可控。遇到特别复杂的业务场景,我有时会选择编写自定义ResultHandler,虽然增加了开发成本,但获得了完全的灵活性。
3.4 查询结果的分页与排序处理
关联查询的分页是个技术难点。如果直接在包含collection的查询上应用分页,可能出现数据截断问题——因为连接查询可能使主表记录重复,PageHelper等分页插件计算的总数会不准确。
我的经验是采用两次查询策略:先分页查询主表ID列表,再根据ID列表查询完整的关联数据。虽然多了一次数据库交互,但分页准确率百分之百。Java优学网的课程列表页就是这样实现的,先分页查询课程ID,再根据ID列表查询课程详情和关联的分类信息。
排序处理相对简单,可以在主查询的SQL中直接添加order by子句。但要注意,排序字段最好来自主表,避免因连接查询导致的性能问题。关联数据的排序通常放在业务层处理,比如用户文章按发布时间倒序排列,直接在collection的select语句中定义排序规则就好。
4.1 N+1查询问题分析与解决方案
N+1查询问题是关联查询中最常见的性能陷阱。简单来说,当你查询一个主体对象及其关联的N个子对象时,MyBatis默认会先执行1次主查询,然后为每个子对象执行N次额外查询。
我在实际项目中就踩过这个坑。当时查询用户列表及其文章信息,测试数据只有50个用户,每个用户平均10篇文章,系统竟然执行了501次数据库查询!页面加载时间超过5秒,用户体验极差。
解决N+1问题主要有两种思路。一种是使用嵌套结果映射,通过单次SQL连接查询获取所有数据。这种方式减少了数据库往返次数,但可能返回大量冗余数据。另一种是开启全局延迟加载,配合按需加载策略。MyBatis提供了aggressiveLazyLoading和lazyLoadingEnabled配置项,合理设置能显著提升性能。
实际开发中,我倾向于根据数据量做选择。关联数据量少时用连接查询,数据量大时用延迟加载。Java优学网的课程详情页就采用了混合策略:课程基本信息立即加载,学员评价列表延迟加载,页面响应速度提升了60%以上。
4.2 缓存机制在关联查询中的应用
MyBatis的两级缓存对关联查询性能影响巨大。一级缓存作用于SqlSession生命周期,二级缓存可跨Session共享。合理使用缓存能避免重复查询,特别是那些不常变动的关联数据。
配置缓存时需要注意序列化问题。如果关联对象没有实现Serializable接口,开启二级缓存会抛出异常。我记得有个项目就因为Category类忘了实现序列化接口,缓存配置一直不生效,排查了半天才发现问题。
对于读写频繁的数据,缓存的更新策略要格外小心。Java优学网的课程信息更新相对频繁,但课程分类数据变化较少。我们把分类数据放入二级缓存并设置较长过期时间,课程基本信息只用一级缓存,这样既保证了性能又确保了数据及时性。
缓存的粒度控制也很重要。不要一股脑缓存整个对象图,应该根据业务场景选择缓存层级。用户基本信息可以缓存,但用户的最新学习记录可能就不适合缓存。
4.3 SQL语句优化技巧
关联查询的SQL优化要从数据库层面入手。避免使用SELECT *,只查询需要的字段能减少网络传输和内存占用。在Java优学网的实践中,我们为每个关联查询定制了专属的结果映射,只包含页面展示必需的字段。
连接查询时注意表连接顺序。一般来说,数据量小的表应该作为驱动表。如果使用嵌套查询,确保子查询使用了正确的索引。有次性能调优时发现,一个看似简单的关联查询执行缓慢,原来是子查询没有利用到复合索引。
分页查询要特别小心。在包含一对多关联的查询上直接分页,由于连接导致的行数膨胀,分页结果往往不准确。我们的做法是先分页查询主键,再用主键列表查询完整数据,虽然多了一次查询,但保证了分页准确性。
EXPLAIN命令是SQL优化的好帮手。定期分析慢查询日志,对执行计划不理想的关联查询进行重构。有时候,把一个大而全的关联查询拆分成多个简单查询,整体性能反而更好。
4.4 索引设计与查询效率提升
合适的索引能让关联查询性能产生质的飞跃。关联字段必须建立索引,这是最基本的优化原则。在Java优学网的数据库设计中,所有外键字段都建立了索引,关联查询的响应时间平均减少了70%。
复合索引的字段顺序很重要。应该把等值查询的字段放在前面,范围查询的字段放在后面。用户文章查询通常按user_id等值过滤,再按create_time排序,所以我们建立了(user_id, create_time)的复合索引。
索引不是越多越好。过多的索引会影响写操作性能,增加存储空间。我们定期使用索引使用率统计,删除那些很少被使用的冗余索引。有个月度清理中,我们删除了15个无用索引,写性能提升了20%。
覆盖索引能进一步提升查询效率。如果查询的所有字段都包含在索引中,数据库可以直接从索引返回数据,避免回表操作。用户基本信息查询我们就设计了覆盖索引,查询速度提升非常明显。
监控工具的使用也很关键。我们使用阿里云的DAS来自动发现慢SQL,定期review关联查询的执行计划。这种主动监控帮我们提前发现了很多潜在的性能问题。
5.1 动态关联查询的实现
动态关联查询让数据查询更加灵活智能。根据不同的业务场景,自动决定是否加载关联数据,或者选择加载哪些关联数据。这种能力在实际项目中非常实用。
我印象很深的一个案例是Java优学网的课程搜索功能。用户搜索课程时,可能只需要课程基本信息,也可能需要查看详细的章节列表和讲师信息。如果每次都加载所有关联数据,性能肯定吃不消。
MyBatis提供了多种实现动态关联的方式。通过<if>标签在resultMap中动态配置association和collection是最直接的方法。也可以在查询方法中传递参数,控制是否执行关联查询。更高级的做法是使用拦截器,在运行时动态修改SQL和结果映射。
参数化查询是另一个实用技巧。在association或collection标签的column属性中使用OGNL表达式,根据主查询结果动态决定关联查询的参数。这样就能实现“智能关联”,只加载当前业务场景真正需要的数据。
动态关联查询需要平衡灵活性和复杂性。配置过于复杂会降低代码可维护性,过于简单又无法满足业务需求。我的经验是建立一套清晰的策略规则,让动态关联的行为可预测、可调试。
5.2 自定义结果映射处理
默认的结果映射有时无法满足复杂的数据结构需求。自定义结果映射给了我们更大的控制权,能够处理各种特殊的映射场景。
Java优学网的订单系统就遇到了这样的需求。订单需要关联用户信息、课程信息、支付记录等多个对象,但返回的数据结构要扁平化,方便前端展示。默认的嵌套映射会产生多层嵌套的JSON,不符合接口规范。
自定义TypeHandler是解决这类问题的利器。我们可以为特定的字段类型编写自定义的类型处理器,在数据读取时进行转换。比如把数据库中的逗号分隔字符串,转换成List对象返回给前端。
ResultHandler接口提供了更底层的控制。通过实现自定义的ResultHandler,我们可以完全掌控结果集的处理过程。虽然代码量会增加,但灵活性是无可比拟的。
实际使用中要注意性能影响。自定义处理逻辑通常比默认映射慢,特别是处理大数据集时。我们会在关键的复杂查询上使用自定义映射,简单查询还是优先使用默认配置。
5.3 关联查询的异常处理
关联查询的异常处理往往被忽视,直到线上出现问题才追悔莫及。健全的异常处理机制是系统稳定性的重要保障。
最常见的异常是关联数据不存在。比如查询用户详情时关联查询用户扩展信息,但扩展信息记录可能被删除。默认情况下MyBatis会抛出异常,导致整个查询失败。
配置notNullColumn属性可以避免部分空值异常。指定哪些列必须不为空,当这些列为空时就不创建关联对象。这种方式能处理简单的空关联场景,但复杂的异常情况还需要更细致的控制。
全局异常处理结合事务回滚是更安全的做法。我们在Service层统一捕获数据库异常,根据异常类型决定是否回滚事务。对于可恢复的异常,比如单条关联记录查询失败,会记录日志并继续处理其他数据。
监控和告警同样重要。Java优学网建立了完整的异常监控体系,关联查询异常会实时告警。有次线上环境数据库网络波动导致大量关联查询超时,监控系统立即告警,我们在用户感知前就完成了故障处理。
5.4 实际项目中的经验总结
多年的MyBatis使用经验让我积累了一些宝贵的心得。这些经验可能不会出现在官方文档中,但对项目成功至关重要。
代码可读性比性能优化更重要——在大多数情况下。过度优化的关联查询往往难以理解和维护。我宁愿牺牲一点性能,也要保证代码的清晰易懂。团队成员能够快速理解并修改代码,这个价值远大于那几毫秒的性能提升。
测试覆盖率是关联查询稳定性的基石。我们为每个复杂的关联查询都编写了完整的单元测试和集成测试。测试要覆盖各种边界情况:空关联、循环关联、大数据量关联等。这套测试体系多次帮我们提前发现了潜在问题。
文档和注释不可或缺。关联查询的复杂度较高,清晰的文档能大大降低维护成本。我们在每个复杂的resultMap上都添加了详细的注释,说明设计意图和注意事项。新同事接手项目时,这些文档发挥了巨大作用。
技术选型要结合实际团队能力。MyBatis的关联查询很强大,但如果团队对SQL不熟悉,可能会适得其反。有时候,在Service层手动组装数据反而是更好的选择。技术没有绝对的好坏,只有适合与否。
最后,保持学习的心态很重要。MyBatis在不断进化,新的特性和最佳实践不断涌现。定期回顾和重构现有的关联查询,你会发现总有改进的空间。技术在变,业务在变,我们的实践也要随之进化。