public void readFile(String filename) throws IOException {
// 方法实现
}
// 正确的语法位置 public void readConfig(String filePath) throws IOException {
// 方法实现
}
3.1 两种异常处理方式的本质区别
throws和try-catch在异常处理中扮演着完全不同的角色。throws更像是一个接力棒传递者,把异常沿着调用链向上抛出,直到找到合适的处理者。而try-catch则是异常处理的终点站,在这里异常被捕获并得到实际处理。
从责任分配的角度看,throws将异常处理的责任转移给了调用者,调用者必须决定如何处理这个异常或者继续向上抛出。try-catch则是当前方法主动承担起处理异常的责任。
代码的执行流程也体现了这种差异。使用throws时,异常发生后方法会立即终止执行,控制权交还给调用者。try-catch则允许在捕获异常后继续执行后续代码,或者进行清理工作。
我记得重构一个老项目时遇到的情况。原来的代码在多层方法调用中都使用try-catch,导致相同的异常处理逻辑在各个层级重复出现。改用throws后,异常处理逻辑集中到了最合适的业务层,代码立即变得清爽很多。
3.2 适用场景的对比选择
选择throws还是try-catch,很大程度上取决于异常处理的上下文和职责边界。
throws更适合工具类方法、底层服务方法。这些方法通常不具备处理异常的业务上下文,强行在方法内部处理反而可能掩盖问题。比如一个文件读取方法,它不知道调用者是否需要重试、记录特定日志或向用户显示错误信息。

try-catch则更适合顶层业务方法、用户交互层。这些地方有足够的上下文信息来决定如何向用户展示错误,或者如何进行业务补偿操作。Web应用中的控制器方法通常使用try-catch来捕获业务异常,然后转换为用户友好的错误信息。
另一个考量因素是异常的可恢复性。对于可恢复的异常,在当前方法中使用try-catch进行重试或替代方案处理是合理的。对于不可恢复的系统级异常,使用throws让异常向上传播可能更合适。
在实际项目中,我倾向于在服务层使用throws,在表现层使用try-catch。这样的分层处理让异常处理逻辑更加清晰,每层只关注自己应该处理的异常类型。
3.3 性能与代码可读性考量
从性能角度分析,两种方式并没有显著差异。Java异常处理的性能开销主要在于异常对象的创建和栈跟踪信息的收集,而不是异常传播机制本身。
代码可读性方面,适当地使用throws可以让方法签名更清晰地表达其异常抛出行为。调用者从方法声明就能知道需要处理哪些异常。但过度使用throws,特别是在声明过于宽泛的异常类型时,会降低代码的可读性。
try-catch块如果嵌套过深,或者catch块中处理逻辑过于复杂,同样会影响代码的可读性。理想的做法是保持catch块的简洁,复杂的处理逻辑可以抽取到单独的方法中。
维护性也是重要考量。使用throws的代码通常更容易进行单元测试,因为异常行为可以通过方法签名明确预期。而try-catch中的异常处理逻辑可能需要更多的测试用例来覆盖。

平衡点在于,既不要让异常无声无息地被吞噬,也不要让异常处理代码喧宾夺主,掩盖了正常的业务逻辑。好的异常处理应该像优秀的幕后工作人员,平时不引人注目,关键时刻能够妥善处理各种意外情况。
4.1 合理的异常传递策略
异常传递策略的核心在于找到处理异常的最佳位置。就像接力赛跑,每个选手只负责自己那段路程,把接力棒交给最适合完成下一段的人。
在分层架构中,数据访问层通常抛出特定的数据访问异常,服务层捕获这些异常并转换为业务异常,表现层最终处理业务异常并展示给用户。这种分层传递确保了每层只处理自己职责范围内的异常类型。
异常包装是另一个重要技巧。底层抛出的技术异常可以在服务层包装成更有业务含义的自定义异常。比如将SQLException包装为DataAccessException,这样上层代码就不需要关心具体的数据访问技术细节。
我参与过一个电商项目,最初所有层都直接抛出SQLException。后来我们将数据层异常统一包装为RepositoryException,业务层异常包装为BusinessException,前端只需要处理几种明确的异常类型,代码维护性大幅提升。
4.2 避免过度使用throws的陷阱
throws关键字用得好是利器,用过头就成负担。最常见的陷阱是在每个方法签名中都声明throws Exception,这种偷懒的做法让调用者无法明确知道具体会抛出哪些异常。
检查性异常的处理需要特别小心。如果某个检查性异常在当前方法中无法合理处理,向上抛出是正确选择。但如果调用链上的每个方法都只是简单地重新抛出,最终可能让异常一直传递到main方法,这显然不是好的设计。
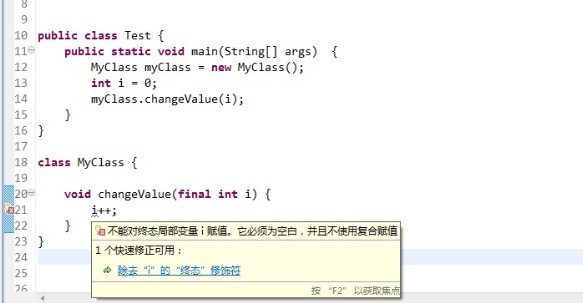
另一个常见问题是异常声明的粒度太粗。声明throws Exception就像说“我可能抛出任何异常”,这种模糊的声明让调用者无从下手。应该尽可能声明具体的异常类型,让调用者明确知道需要处理哪些情况。
运行时异常的使用也需要节制。虽然RuntimeException不需要在方法签名中声明,但过度依赖运行时异常可能导致重要的错误条件被忽略。关键的业务异常最好还是定义为检查性异常。
4.3 与自定义异常的结合使用
自定义异常与throws关键字的结合,能让异常处理更加精准和具有业务含义。当标准Java异常无法准确描述业务场景时,创建自定义异常是明智的选择。
创建自定义异常时,考虑异常的继承层次很重要。业务异常通常继承自Exception,技术异常可能继承自RuntimeException。清晰的异常层次结构有助于调用者进行针对性的异常处理。
异常信息的设计也值得关注。自定义异常应该提供有意义的错误信息和错误码,方便调用者理解和处理。但要注意避免在异常消息中暴露敏感信息,比如数据库连接细节或用户隐私数据。
异常链的保持很重要。创建自定义异常时,记得将原始异常作为cause传递进去。这样在日志中就能看到完整的异常堆栈,便于问题排查。
我曾见过一个支付系统,为不同的支付失败原因定义了十几种自定义异常。虽然看起来有些复杂,但这种精细化的异常设计让错误处理变得非常精确,系统运维效率明显提高。
好的异常设计就像城市的交通标志,既不能太少导致迷路,也不能太多让人眼花缭乱。找到那个平衡点,你的代码就会既健壮又清晰。 public class ConfigReader {
public String readConfig(String filePath) throws FileNotFoundException, IOException {
// 这个方法声明了两个检查性异常
File file = new File(filePath);
if (!file.exists()) {
throw new FileNotFoundException("配置文件不存在: " + filePath);
}
return Files.readString(Paths.get(filePath));
}
}