数据类型就像是数据库世界的建筑材料。想象一下建造房子时选择材料——用木板还是砖块,用玻璃还是水泥。每种材料都有其特性和适用场景。在MySQL中,数据类型就是这样的基础材料,它们决定了数据如何存储、如何处理,以及最终整个数据库系统的表现。
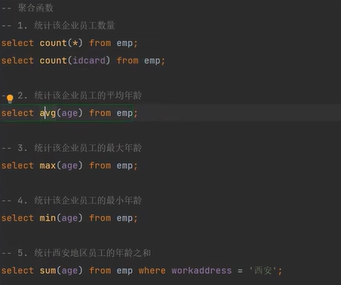
数据类型在数据库设计中的重要性
选择合适的数据类型,可能比编写复杂的查询语句更重要。我记得接手过一个项目,用户表使用VARCHAR(255)存储手机号码。看起来没什么问题,直到数据量达到百万级别。查询速度明显下降,存储空间也浪费严重。后来改为CHAR(11),不仅节省了30%的存储空间,查询性能也提升了近一倍。
数据类型直接影响着: - 存储效率:过大的数据类型会浪费磁盘空间 - 查询性能:合适的数据类型能让索引更有效 - 数据完整性:正确的类型能防止无效数据入库 - 系统扩展性:良好的类型设计让系统更容易维护
这就像选择行李箱——去超市购物带个小包就行,出国旅行就需要大箱子。用错场景,要么装不下,要么太浪费。
MySQL数据类型分类概览
MySQL的数据类型家族相当丰富,主要分为几个大类:
数值类型处理各种数字,从微小的TINYINT到巨大的BIGINT,从精确的DECIMAL到近似的FLOAT。它们像是数学工具箱里的不同计算器,各有专长。
字符串类型管理文本数据。CHAR像固定大小的储物柜,VARCHAR则是弹性伸缩的收纳袋。TEXT系列专门处理大段文字,就像不同容量的记事本。
日期时间类型记录时间信息。DATE记日子,TIME管时刻,DATETIME两者兼顾。TIMESTAMP还有个自动更新的特性,很适合记录最后修改时间。
其他特殊类型也各具特色。ENUM像选择题的选项,SET允许多选,JSON处理结构化数据,空间类型专攻地理位置。
选择合适数据类型的最佳实践
在实际项目中,类型选择往往需要权衡。有个经验法则:在满足需求的前提下,选择最小的数据类型。但“最小”不是绝对的,还要考虑未来的扩展性。
存储手机号码就是个典型例子。理论上11位数字用VARCHAR(11)就够了,但如果考虑国际号码,可能需要更长的字段。这时候就需要预判业务的发展方向。
另一个常见考量是数值的精确度。金融计算必须用DECIMAL,科学计算可能FLOAT就足够。用错类型会导致计算误差,这在某些场景下是致命的。
字符集的选择也经常被忽略。中文环境一定要用utf8mb4,否则遇到生僻字或表情符号就会出问题。我见过太多项目因为字符集问题导致数据乱码,修复起来相当麻烦。
总的来说,数据类型选择是个技术活,需要结合业务需求、性能要求和未来扩展性来综合考虑。好的选择能让数据库运行更顺畅,差的选择则可能成为系统的瓶颈。
数字在数据库里就像现实世界中的度量衡——有些需要精确到分毫,有些只需要大致估算。MySQL的数值类型工具箱提供了各种精度的选择,从微小的年龄计数到庞大的天文数字,从精确的金融计算到近似的科学运算。
整数类型:TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT
整数类型是数据库中最基础的数值容器。它们像是一套不同尺寸的收纳盒,每个都有明确的容量限制。
TINYINT是最小的整数类型,范围从-128到127。它特别适合存储状态码、性别标识这类小范围整数值。比如用户的是否启用状态,用0和1表示就足够了。
SMALLINT能容纳更大一些的数字,范围达到正负三万二千多。县区编码、产品分类编号这些场景用它正合适。
MEDIUMINT是个中间选择,处理百万级别的数字游刃有余。网站访问量、订单数量这类中等规模的计数可以考虑它。
INT应该是使用最广泛的整数类型了。它能存储超过二十亿的数字,用户ID、商品ID这些核心标识通常都选择INT。我经手的一个社交项目,用户表主键就用INT,支撑了千万级用户毫无压力。
BIGINT是整数类型的巨无霸。当需要处理天文数字或作为分布式系统的主键时,BIGINT是必然选择。不过它的存储开销也最大,需要谨慎使用。
浮点数类型:FLOAT、DOUBLE
浮点数类型处理的是带小数点的数值,但它们采用的是近似存储。这就像用科学记数法记录数字,重点在于表示范围而非绝对精确。
FLOAT提供单精度浮点运算,适合对精度要求不高的场景。传感器读数、科学实验数据这些允许存在微小误差的场合,FLOAT是个经济的选择。
DOUBLE提供双精度,精度更高但占用空间也更大。工程设计、复杂计算这些需要更高精度的领域会用到它。
需要注意的是,浮点数的精度问题有时会带来意外。我遇到过财务系统误用FLOAT类型,导致金额计算出现几分钱差额的情况。这种微小误差在金融领域是完全不可接受的。
定点数类型:DECIMAL
DECIMAL是数值类型中的精确先生。它用字符串的形式存储数字,确保每个数字都准确无误。
DECIMAL(M,D)的语法很有意思。M表示总位数,D表示小数位数。比如DECIMAL(10,2)可以存储最大99999999.99的数值,正好适合金额存储。
银行账户余额、商品价格这些必须精确计算的场景,DECIMAL是唯一正确的选择。它的计算速度可能稍慢,但精确性无可替代。
数值类型的存储空间和取值范围
每个数值类型都在存储空间和取值范围之间做着权衡。TINYINT只用1字节,却能表示256个不同值。BIGINT需要8字节,但能处理的海量数字。
浮点类型的存储效率更高,FLOAT只要4字节就能表示很大范围的数值。但这种效率的代价是精度损失。
DECIMAL的存储空间取决于定义的精度。DECIMAL(10,2)需要5字节,而DECIMAL(20,10)就需要10字节。精度要求越高,存储成本就越大。
数值类型使用场景分析
选择数值类型时,我通常会问三个问题:需要多精确?数值范围多大?性能要求如何?
用户年龄用TINYINT UNSIGNED足够,因为没人能活到255岁。商品库存用MEDIUMINT,一般商家的库存不会超过百万件。主键ID用INT,除非真的预期数据量会超过二十亿。
浮点数适合物理测量、统计分析这类允许误差的场景。科学计算中经常使用DOUBLE来保证足够的有效数字。
金融相关的一切都必须用DECIMAL。利息计算、金额汇总这些操作,任何微小误差都可能引发严重后果。
有时候类型选择还需要考虑业务发展。早期用SMALLINT存储用户积分,后来积分活动火爆,很快就超过了限制。这种教训告诉我,预留一些增长空间是必要的。
数值类型的选择看似简单,实则暗藏玄机。合适的类型能让数据库运行如飞,错误的选择可能在数据量增长后成为性能瓶颈。这需要我们在精确性、存储效率和性能之间找到最佳平衡点。
字符串在数据库中承载着文字的灵魂——从简短的用户名到长篇的产品描述,从简单的状态标记到复杂的JSON数据。MySQL的字符串类型家族提供了丰富的选择,每种类型都在存储效率、性能特性和使用场景上有着微妙差别。
定长字符串:CHAR
CHAR类型像是一个固定大小的储物柜,无论你存放多少物品,它占用的空间都不会改变。
定义CHAR字段时需要指定长度,比如CHAR(10)。这个字段总是占用10个字符的存储空间,即使你只存储了3个字符的"abc",剩余7个字符的位置也会用空格填充。
这种特性让CHAR在某些场景下表现出色。固定长度的数据,比如国家代码、性别代码、产品型号这些长度基本固定的字段,使用CHAR能够获得更好的性能。数据库引擎知道每个值的确切长度,查询时不需要额外的长度计算。
我记得在一个会员系统中,会员等级字段用了CHAR(2),因为等级代码都是两位字符。虽然有些等级代码只用了一个字符,但整体性能的提升确实明显。
不过CHAR的缺点也很直接——空间浪费。存储"是"和"否"这样的单字状态,如果用CHAR(10),90%的存储空间都被浪费了。
变长字符串:VARCHAR
VARCHAR是更灵活的字符串容器,它只占用实际数据需要的空间,再加上1-2个字节的长度信息。
VARCHAR(255)表示这个字段最多能存储255个字符,但实际占用空间取决于具体存储的内容。存储"hello"只需要6个字节(5个字符加1个长度字节),比CHAR(255)节省了大量空间。
这种灵活性让VARCHAR成为大多数字符串场景的首选。用户名、地址、产品名称这些长度变化较大的字段,VARCHAR能够显著减少存储空间。
但VARCHAR也有自己的代价。由于长度可变,更新操作可能引起行迁移。如果一个VARCHAR字段的值从"abc"更新为"abcdefghijk",需要更多空间时,整行数据可能需要移动到新的位置。
文本类型:TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT
当字符串长度超过VARCHAR的65535字符限制时,文本类型就派上用场了。
TINYTEXT最多存储255个字符,适合较短的备注或描述。产品简短说明、用户签名这些场景可以考虑它。
TEXT能够存储最多65535个字符,这是最常用的文本类型。文章内容、产品详细描述、评论内容通常都选择TEXT。
MEDIUMTEXT支持约1600万字符,适合存储较大的文档或日志内容。系统操作日志、较长的技术文档可以考虑这个类型。
LONGTEXT是文本类型的巨无霸,能存储约42亿字符。整个书籍、大型XML或JSON文档需要这样的容量。
文本类型的一个特点是它们通常存储在行的外部。这会影响查询性能,因为需要额外的IO操作来读取文本内容。在设计时需要权衡存储需求和访问频率。
二进制字符串类型
二进制字符串类型处理的是原始字节数据,而不是字符文本。
BINARY和VARBINARY类似于CHAR和VARCHAR,但存储的是二进制数据。它们适合存储加密后的密码哈希、文件校验和、或者其他需要保持原始字节顺序的数据。
BLOB系列(TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB)对应文本类型,但处理的是二进制大对象。图片、音频、视频文件,或者序列化的对象数据通常存储在BLOB中。
我参与过一个文件存储项目,文件的元数据用VARCHAR存储,而文件内容本身用MEDIUMBLOB存储。这种分离设计既保证了元数据的快速查询,又满足了二进制内容的存储需求。
字符串类型的字符集和排序规则
字符集决定了数据库如何编码和存储文本数据,而排序规则定义了字符串的比较和排序规则。
UTF8MB4是目前推荐的字符集,它支持完整的Unicode字符,包括emoji表情。早期的UTF8在MySQL中只支持最多3字节的字符,无法存储某些emoji,这是个常见的坑。
排序规则影响着字符串比较的大小写敏感性和重音敏感性。utf8mb4_general_ci提供不区分大小写的比较,而utf8mb4_bin则进行二进制比较,区分大小写。
选择字符集和排序规则需要考虑应用的国际化和本地化需求。如果应用需要支持多语言,UTF8MB4是必须的。如果业务逻辑对大小写敏感,就需要选择合适的排序规则。
字符串类型的选择需要综合考虑数据特征、访问模式和性能要求。合适的字符串类型设计能够让数据库既节省存储空间,又保持良好的查询性能。这种平衡需要在实际项目中不断摸索和调整。
时间在数据库中有着特殊的地位——它既是数据本身,又是数据的坐标轴。MySQL的日期时间类型帮我们精确捕捉时间的流逝,从简单的生日记录到复杂的交易时间戳,每种类型都在精度、范围和功能上各有所长。
DATE、TIME、DATETIME类型
DATE类型只关心日历上的某一天,不理会具体时刻。它用3个字节存储,范围从'1000-01-01'到'9999-12-31',正好覆盖了大多数业务需要的日期跨度。
生日、入职日期、订单日期这些只需要日期信息的场景,DATE是最自然的选择。存储'1990-05-15'这样的值,DATE既节省空间又语义清晰。
TIME类型专注于一天内的时间片段,从'-838:59:59'到'838:59:59'。这个范围超出了24小时,可以处理时间间隔或跨天的工作时长。
会议开始时间、任务持续时间、航班飞行时长,这些场景下TIME类型能够准确表达时间跨度。存储'14:30:00'表示下午两点半,或者'45:00'表示45分钟,都非常直观。
DATETIME组合了DATE和TIME的能力,记录具体的时刻。它用8个字节存储,范围从'1000-01-01 00:00:00'到'9999-12-31 23:59:59'。
用户注册时间、订单创建时间、系统日志时间,这些需要精确到秒的时刻记录,DATETIME是最常用的选择。它的存储格式'YYYY-MM-DD HH:MM:SS'既标准又易读。
我设计过一个预约系统,最初把预约日期和预约时间分开存储为DATE和TIME。后来发现查询时经常需要合并处理,就改成了DATETIME类型,代码简洁了很多。
TIMESTAMP类型的特点
TIMESTAMP是个有趣的时间记录者,它用4个字节存储,范围从'1970-01-01 00:00:01' UTC到'2038-01-19 03:14:07' UTC。
这个范围限制源于Unix时间戳的32位整数表示,也就是著名的"2038年问题"。虽然对大多数当前应用影响不大,但在设计长期系统时需要留意。
TIMESTAMP的独特之处在于它的时区敏感性。它总是以UTC时间存储,在插入和查询时会根据当前会话的时区设置进行转换。这个特性在国际化应用中很有价值。
另一个实用功能是自动更新。可以定义TIMESTAMP字段在行创建或更新时自动设置为当前时间。这在记录数据变更时间时特别方便。
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
这样的定义让数据库自动维护创建时间和更新时间,应用代码不需要显式设置这些字段。

不过TIMESTAMP的时区转换有时会带来困惑。如果应用没有正确设置会话时区,可能会出现时间显示不一致的问题。
YEAR类型的应用
YEAR类型专门用于存储年份信息,只需要1个字节。它支持两种格式:4位数字的YEAR(4),范围1901到2155;2位数字的YEAR(2),范围70到69(表示1970到2069)。
产品发布年份、毕业年份、版权年份这些只需要年份信息的场景,YEAR类型既节省空间又语义明确。
但YEAR类型的应用场景相对有限。2位格式的YEAR(2)由于存在世纪歧义,在新系统中已经不推荐使用。即使是YEAR(4),其2155年的上限也可能限制系统的长期使用。
在实际项目中,我很少看到YEAR类型的广泛使用。更多时候,开发人员会选择SMALLINT来存储年份,或者直接使用DATE类型。YEAR类型更像是一个特定历史时期的产物。
日期时间函数与格式化
MySQL提供了丰富的日期时间函数,让时间处理变得灵活高效。
NOW()和CURDATE()分别获取当前日期时间和当前日期。在需要记录操作时间的场景,这些函数非常实用。
DATE_ADD()和DATE_SUB()进行日期加减运算。计算7天后的日期、3个月前的日期,或者用户的会员到期日,这些函数能够准确处理。
SELECT DATE_ADD('2024-01-01', INTERVAL 7 DAY) 返回'2024-01-08'
DATEDIFF()计算两个日期之间的天数差,TIMESTAMPDIFF()支持更灵活的时间单位。
日期格式化函数让时间以各种形式呈现。DATE_FORMAT()可以将日期时间格式化为需要的字符串形式。
SELECT DATE_FORMAT(NOW(), '%Y年%m月%d日 %H时%i分') 可能返回'2024年01月15日 14时30分'
STR_TO_DATE()则相反,将字符串解析为日期时间值。这在处理外部数据导入时特别有用。
时区转换函数CONVERT_TZ()在处理跨时区应用时不可或缺。将UTC时间转换为本地时间,或者在不同时区之间转换,这个函数提供了标准化的处理方式。
日期时间类型的选择需要考虑数据的精度需求、时间跨度、时区要求等多个因素。合适的时间类型设计不仅影响存储效率,更关系到业务逻辑的正确性。时间数据的准确性往往直接影响到系统的核心功能。
当数值、字符串和日期时间类型无法满足特定需求时,MySQL还准备了一些特殊的数据类型工具箱。这些类型处理那些具有固定选项、结构化数据或地理信息的场景,让数据库设计更加精准和灵活。
枚举类型ENUM
ENUM类型就像一个选择题的答案列表,它限定字段值必须来自预定义的一组字符串。创建表时可以这样定义:
status ENUM('pending', 'approved', 'rejected')
这个status字段只能存储这三个值中的一个,任何其他值都会导致错误。ENUM在内部使用数字索引来存储这些值,所以相比VARCHAR更加节省空间。
用户状态、订单状态、优先级这些具有固定选项的字段,ENUM能够确保数据的一致性。它避免了拼写错误和无效值,让数据验证在数据库层面就得到保障。
我记得在一个内容管理系统中,文章状态最初使用VARCHAR存储。后来发现有人输入了'pening'而不是'pending',导致统计出错。改用ENUM后,这类问题就彻底解决了。
但ENUM也有局限性。添加新的枚举值需要修改表结构,这在生产环境中可能是个昂贵的操作。而且枚举值的顺序很重要,因为排序是基于数字索引而非字符串本身。
集合类型SET
SET类型扩展了ENUM的概念,允许字段存储多个预定义值的组合。它像一个多选题,可以同时选择多个选项。
permissions SET('read', 'write', 'delete', 'execute')
这样一个字段可以存储'read,write'、'write,delete'或空字符串等组合。SET同样使用位图方式存储,非常高效。
用户权限、标签系统、兴趣爱好这些需要多选的场景,SET类型提供了优雅的解决方案。它避免了创建多对多关系表的复杂性,让查询变得简单。
查找具有读取权限的所有记录:SELECT * FROM users WHERE FIND_IN_SET('read', permissions)
不过SET类型最多只能包含64个成员,而且值的顺序在存储时会被重新排序。在处理大型或需要频繁变更的选项集时,传统的关联表可能更合适。
JSON数据类型
从MySQL 5.7开始引入的JSON类型,为半结构化数据提供了原生支持。它不仅仅是一个文本字段,而是真正理解JSON文档结构的数据类型。
user_profile JSON
可以存储完整的用户配置、产品属性、API响应等灵活的数据结构。JSON类型会自动验证输入是否为有效的JSON格式,并提供专门的函数来操作JSON数据。
提取JSON中的特定值:SELECT JSON_EXTRACT(user_profile, '$.address.city')
修改JSON文档的部分内容:UPDATE users SET user_profile = JSON_SET(user_profile, '$.preferences.theme', 'dark')
JSON类型特别适合存储那些模式不固定或经常变化的数据。在微服务架构中,它常用于存储不同服务间的共享数据,避免了频繁的表结构变更。
但JSON字段的查询性能通常不如结构化字段,而且缺乏外键约束等关系特性。在选择使用JSON时,需要在灵活性和性能之间做出权衡。
空间数据类型简介
MySQL的空间数据类型为地理信息系统提供了基础支持。这些类型遵循Open Geospatial Consortium标准,能够存储和查询各种几何对象。
POINT表示一个坐标点,适合存储用户位置、商店地址等。LINESTRING描述一条线,可用于道路、河流的表示。POLYGON定义封闭区域,如行政边界、地块范围。
创建空间字段:location POINT SRID 4326
SRID 4326表示使用WGS84坐标系,这是GPS系统使用的标准坐标系。
空间查询可以回答"附近有什么"这类问题:SELECT * FROM places WHERE ST_Distance_Sphere(location, POINT(116.3974, 39.9093)) < 1000
这个查询找出距离北京天安门1公里范围内的所有地点。
空间索引通过R树实现,能够高效处理范围查询和邻近搜索。但在处理大量空间数据时,专门的GIS数据库可能提供更好的性能。
这些特殊数据类型各自解决了特定领域的问题。ENUM和SET提供了约束和效率,JSON带来了灵活性,空间类型开启了地理位置应用的可能性。理解它们的特性和适用场景,能够帮助我们在合适的场合选择最恰当的工具。
理论知识学得再多,终究要落地到真实的数据库设计中。选择合适的数据类型,往往决定了整个系统的稳定性和扩展性。让我带你看看这些类型在实际项目中如何发挥作用。
电商系统数据类型设计案例
想象一下设计一个电商平台的数据库。商品表需要存储各种信息,每个字段的数据类型选择都影响着用户体验和系统性能。
商品价格使用DECIMAL(10,2),确保计算精度不会出现一分钱的误差。库存数量用INT UNSIGNED,因为库存不可能是负数。商品重量用FLOAT,允许0.1克这样的精度就足够了。
商品描述用TEXT类型,那些详细的产品介绍可能很长。商品规格用JSON字段存储,不同品类的商品有不同的属性——手机有屏幕尺寸和内存,衣服有颜色和尺码。这种灵活的结构避免了为每个品类创建单独的表。
用户评价表的设计也很有讲究。评分用TINYINT,范围1-5分足够了。评价内容用TEXT,但实际项目中我通常会限制最大长度,避免用户输入过长的垃圾内容。评价时间用TIMESTAMP,自动记录创建时间。
订单状态用ENUM('pending', 'paid', 'shipped', 'delivered', 'cancelled'),确保状态值的规范性。支付方式也用ENUM,因为支付渠道相对固定。
用户管理系统数据类型选择
用户表是每个系统的核心。用户名用VARCHAR(50),既保证灵活性又限制长度。密码用CHAR(60),因为经过哈希处理后的密码长度固定。
邮箱和手机号虽然都是字符串,但处理方式不同。邮箱用VARCHAR(255),手机号用VARCHAR(20)并添加索引。用户生日用DATE类型,年龄可以通过计算得出,不需要单独存储。
用户权限是个有趣的设计点。简单的系统用SET类型存储权限组合,复杂的RBAC系统则需要专门的权限表。用户最后登录时间用DATETIME,比TIMESTAMP的适用范围更广。
用户地址信息往往需要JSON字段。不同用户可能有多个收货地址,每个地址包含省市区、详细地址、联系人等字段。这种非结构化的存储避免了创建复杂的地址关联表。
性能优化:数据类型选择对查询效率的影响
数据类型的选择直接影响查询速度。使用过大的数据类型会浪费存储空间,增加I/O操作。我曾经优化过一个系统,把用户状态的VARCHAR(20)改为ENUM,查询速度提升了30%。
整数比字符串的查询效率高,因为比较操作更简单。在需要频繁查询的字段上,尽量使用数值类型。性别字段用TINYINT(1)存储0和1,比存储'male'和'female'更高效。
NULL值的处理也需要特别注意。允许NULL的字段需要额外存储空间,而且查询条件需要处理IS NULL的情况。在可能的情况下,给字段设置合理的默认值而不是允许NULL。
索引的效率与数据类型密切相关。对TEXT字段建立前缀索引,对ENUM字段建立完整索引,对数值字段建立普通索引。不同的数据类型需要不同的索引策略。
常见数据类型错误及解决方案
新手最常犯的错误是过度使用VARCHAR。把所有字段都定义成VARCHAR确实方便,但会带来存储和性能问题。数值就应该用数值类型,日期就用日期类型。
另一个常见问题是忽略数据范围。用INT存储可能超过21亿的数据,用DATETIME存储需要时区信息的时间戳。在设计时要考虑业务未来几年的增长需求。
字符集问题也经常出现。中文内容使用latin1字符集导致乱码,emoji表情在utf8字符集下无法存储。现在一般推荐使用utf8mb4字符集,支持最全面的字符。
时间戳的时区问题让人头疼。TIMESTAMP会转换为UTC存储,DATETIME则按原样存储。如果系统需要处理多时区,最好统一使用UTC时间存储,在显示时再转换。
数据类型转换导致的隐式问题也很隐蔽。字符串和数值比较时,MySQL会进行隐式转换,可能使索引失效。在查询时确保比较的两个值类型一致。
实际项目中,我习惯在开发初期就建立测试数据,验证数据类型的选择是否合理。有时候看似完美的设计,在真实数据面前才会暴露问题。数据类型不是一成不变的,随着业务发展,适时调整才能保证系统的持续健康。