1.1 JDBC技术发展历程与市场地位
二十多年前Sun公司推出JDBC时,可能没预料到这个API会成为Java生态中如此持久的基石。我记得第一次接触JDBC时还在用JDBC-ODBC桥接器访问Access数据库,那时候每个连接都要手动管理,代码里满是try-catch块。现在回头看,JDBC的演进就像Java语言本身的成长——从最初的简单数据访问工具,逐步发展成企业级应用不可或缺的组件。
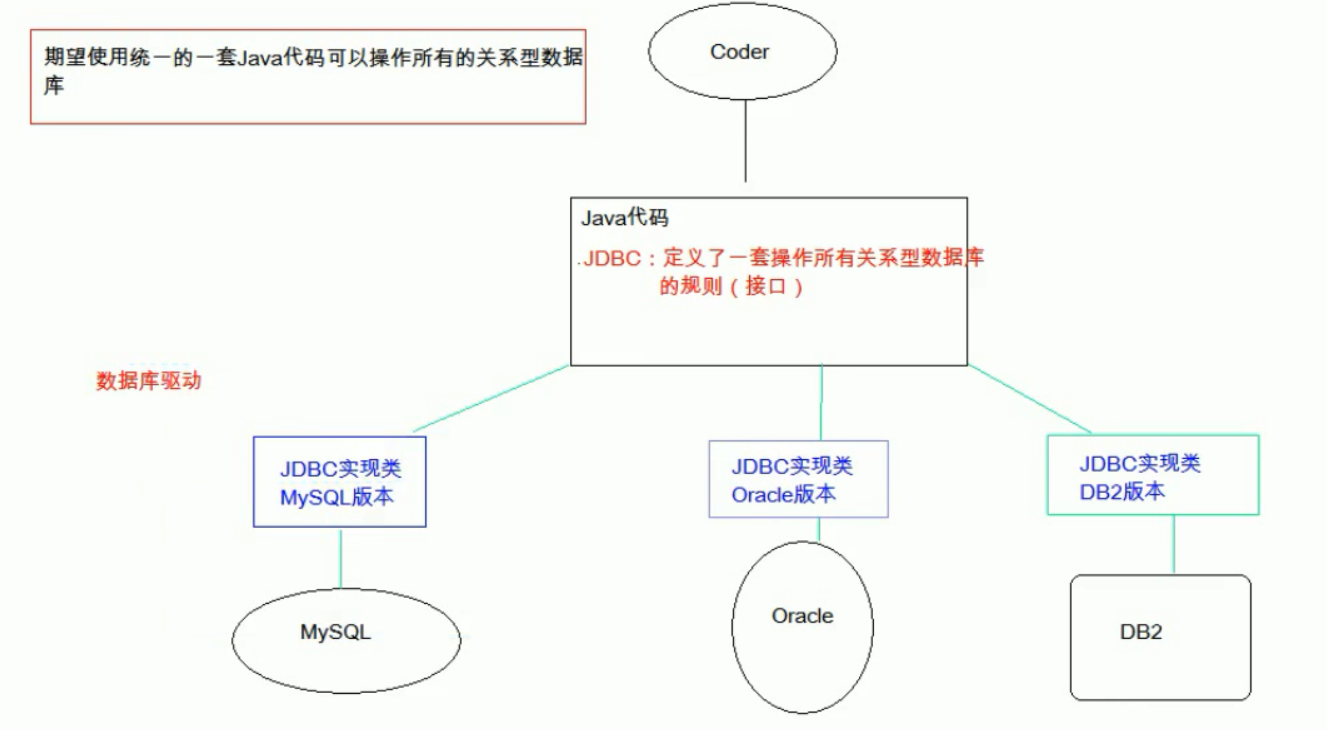
JDBC的市场地位相当稳固。几乎所有主流数据库都提供JDBC驱动,从传统的Oracle、MySQL到新兴的ClickHouse、TiDB。这种广泛的支持让JDBC成为Java开发者与数据库交互的事实标准。即使在云原生和微服务架构流行的今天,JDBC仍然保持着强大的生命力。很多新兴的ORM框架底层依然依赖JDBC,这种设计确实非常明智,既保留了灵活性又提供了抽象层。
1.2 Java优学网JDBC教程特色与竞争优势
我们设计Java优学网JDBC教程时,特别关注学习者的实际痛点。市面上很多教程只讲基础API用法,却忽略了企业开发中的真实场景。我们的课程直接从项目需求出发,比如教你在电商系统中如何处理库存扣减的并发问题,在金融应用中如何确保事务的ACID特性。
教程的竞争优势在于实战性。每个知识点都配有可运行的代码示例,而且这些示例都来自真实的业务场景。我们还提供了大量的“坑点”分析——那些官方文档不会写,但实际开发中一定会遇到的问题。比如连接泄露的排查技巧,结果集内存溢出的预防措施。这种经验性的内容,往往是区分初级和高级开发者的关键。
1.3 当前企业级应用对JDBC技能需求分析
最近帮朋友公司面试Java开发,发现一个现象:很多候选人能说出Spring Data JPA的用法,但对底层的JDBC机制理解很模糊。这其实反映了当前市场的技能断层。企业级应用对JDBC技能的需求正在分层:基础层面要求能熟练使用JDBC API,高级层面则需要理解性能优化和故障排查。
从招聘需求来看,企业特别看重这几个方面的JDBC能力:连接池的配置和调优经验,大数据量下的批处理操作,分布式事务的理解,还有SQL注入的防范意识。我见过一个案例,某电商系统因为不当的JDBC配置,在促销期间数据库连接耗尽,直接导致服务不可用。这种问题往往需要深厚的JDBC功底才能快速定位和解决。
现在的趋势是,企业更青睐那些既懂高级框架,又能深入底层的“全栈式”Java开发者。JDBC作为数据访问的根基,其重要性反而在技术栈不断演进的背景下更加凸显。
2.1 数据库连接配置与优化策略
打开数据库连接看似简单,背后却藏着不少学问。记得有次排查生产环境问题,发现应用启动时总有几个连接超时,最后发现是网络防火墙规则导致的。这个经历让我意识到,连接配置不仅仅是写对URL那么简单。
驱动类加载就有多种方式,Class.forName()是最经典的做法,但现在更多使用DriverManager自动注册。连接字符串里的参数设置直接影响性能,比如useServerPrepStmts启用服务端预处理,cachePrepStmts缓存预处理语句,这些参数在不同数据库驱动中都有差异。连接超时时间设置也是个经验活,太短容易在网络波动时失败,太长则会影响故障恢复速度。
连接数配置需要根据应用负载动态调整。最大连接数不是越大越好,我曾经见过一个配置了500个最大连接的应用,实际上数据库根本支撑不了这么多并发。最佳实践是根据数据库的max_connections参数和应用线程数来综合计算,通常预留20%的缓冲空间。
2.2 SQL语句执行与结果集处理机制
Statement和PreparedStatement的选择往往能看出开发者的经验水平。新手喜欢直接用Statement,老手则倾向于PreparedStatement。不只是防SQL注入,预处理语句的性能优势在重复执行时特别明显。数据库可以缓存执行计划,减少解析开销。
结果集处理有个容易忽略的细节:默认的ResultSet是不可滚动的,只能在next()方法中向前移动。需要可滚动的结果集时,要在创建Statement时指定TYPE_SCROLL_INSENSITIVE。但要注意,可滚动结果集的内存消耗会更大。
大数据量查询时,设置fetchSize很重要。JDBC默认是一次性把所有数据加载到内存,遇到百万级数据时很容易OOM。合理设置fetchSize可以让驱动分批获取数据,我一般根据数据行大小和可用内存来计算这个值。记得有次优化报表查询,仅仅调整了fetchSize就从30秒降到3秒。
2.3 事务管理与并发控制实现方案
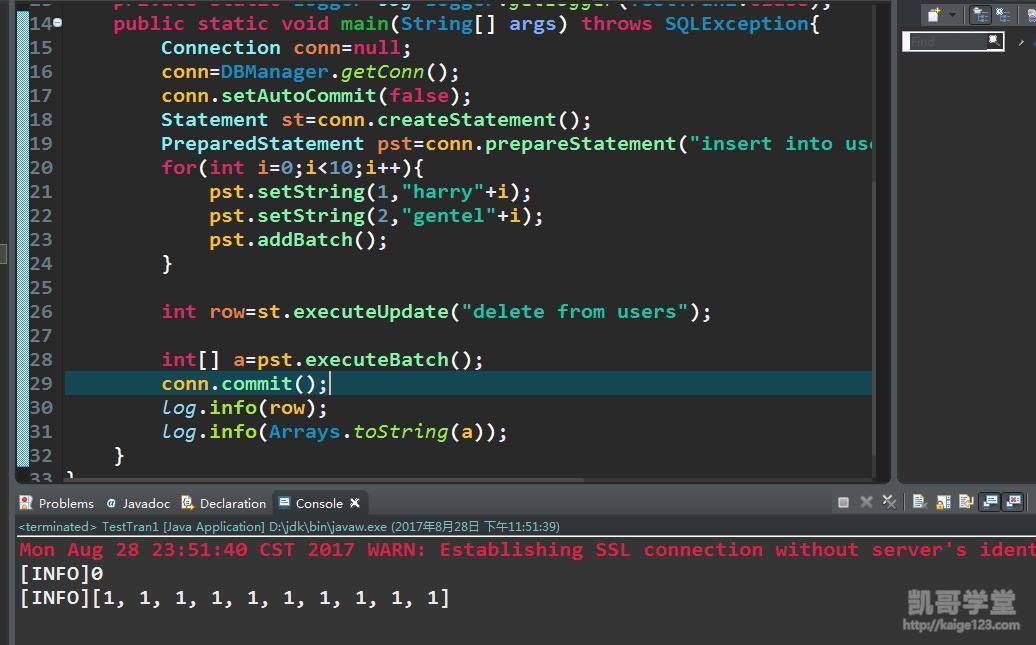
setAutoCommit(false)只是事务管理的开始。事务隔离级别的选择直接影响应用的并发性能和数据一致性。READ_COMMITTED是最常用的级别,但在某些金融场景下可能需要SERIALIZABLE。隔离级别越高,性能代价越大,这是个典型的权衡问题。
保存点(Savepoint)是个很有用的特性,可以在事务内部设置回滚点。比如处理一个多步骤的业务流程时,某一步失败可以回滚到特定步骤,而不是整个事务都回滚。这个特性在大事务中特别实用。
分布式事务通过JTA实现,但JDBC本身也支持XA数据源。实际项目中,我更倾向于避免分布式事务,而是通过业务设计来化解。比如通过消息队列实现最终一致性,这样系统的复杂度会降低很多。
2.4 连接池技术在企业环境中的应用
没有连接池的JDBC应用就像没有刹车的汽车——能开,但很危险。连接池的核心价值在于复用连接,避免频繁创建和销毁的开销。Tomcat JDBC Pool和HikariCP是目前最流行的选择,HikariCP以其高性能著称。
连接池配置需要关注几个关键参数:最大连接数、最小空闲连接、连接最大存活时间、空闲超时时间。这些参数需要根据具体业务特点来调整。高并发应用可能需要较大的最大连接数,而长时间空闲的应用应该设置较小的最小空闲连接来节省资源。
连接泄漏是生产环境的常见问题。好的连接池都提供泄漏检测功能,比如HikariCP可以设置leakDetectionThreshold。我还习惯在代码中使用try-with-resources语法,这样能确保连接在使用后正确关闭。监控连接池的运行状态也很重要,包括活跃连接数、空闲连接数、等待获取连接的线程数等指标。
3.1 典型电商系统数据库操作实现
电商系统的数据库操作特别考验JDBC功底。商品查询、库存扣减、订单生成,每个环节都需要精准的数据库交互。我参与过一个中型电商项目,商品列表分页查询最初要3秒多,后来发现是分页逻辑写得太重。
分页查询优化其实有技巧。不要用内存分页,应该在SQL层面完成。MySQL的LIMIT,Oracle的ROWNUM,不同数据库语法不同但原理相通。更关键的是要避免深度分页,当用户翻到第100页时,OFFSET 1000的性能会很差。我们后来改用游标分页,基于最后一条记录的ID进行查询,性能提升很明显。
库存扣减必须考虑并发。update product set stock=stock-1 where id=? and stock>0,这个简单的SQL在并发下可能超卖。我们开始用乐观锁,但高并发时重试次数太多。最后改用select for update加悲观锁,虽然性能有损失,但保证了数据准确性。电商场景下,宁可慢一点也要保证正确。
3.2 金融行业事务处理最佳实践
金融系统对事务的要求近乎苛刻。转账操作必须保证原子性,扣款和加款要么都成功,要么都失败。我见过一个转账失败的案例,因为异常处理不当,只扣了款却没有加款,用户直接投诉到银监会。
事务边界划分很重要。不要把整个业务流程放在一个大事务里,那样锁持有时间太长。但也不能拆得太碎,失去原子性保证。我们的做法是:核心资金操作在一个短事务内完成,后续的日志记录、消息发送等操作放在事务外异步处理。
金融系统还需要考虑幂等性。网络超时可能导致客户端重试,如果服务端不做幂等控制,一笔转账可能执行两次。我们在关键业务表增加了请求流水号唯一索引,重复的请求直接返回成功,避免资金风险。
3.3 高并发场景下的性能优化方案
高并发下,每个毫秒都很珍贵。连接池配置不当可能成为瓶颈,我们有个系统在促销时出现大量获取连接超时。分析发现是最大连接数设置太小,而获取连接超时时间又设得太长,线程大量堆积。
批处理能极大提升性能。比如批量插入用户操作日志,用addBatch()和executeBatch()比单条插入快10倍以上。但批处理大小需要测试,不是越大越好。我们测试发现1000条左右的批处理大小在大多数场景下效果最佳。
SQL优化往往能带来意想不到的效果。一个复杂的多表关联查询,拆成多个简单查询有时反而更快。数据库的查询优化器不是万能的,我们经常需要手动干预。explain命令是必备工具,执行计划能告诉你索引是否生效,有没有全表扫描。
3.4 实际项目开发中的常见问题与解决方案
连接泄漏是最常见的问题之一。开发者在try块里获取连接,在finally块里关闭,看似完美,但如果close()方法也抛异常呢?我们要求所有数据库操作必须用try-with-resources,这是Java 7引入的语法,能保证资源一定被关闭。
字符集问题经常被忽略。中文变成问号,通常是连接字符串没指定字符集。jdbc:mysql://localhost:3306/db?useUnicode=true&characterEncoding=UTF-8,这个参数组合能解决大部分中文乱码问题。但要注意,不同数据库的字符集参数可能不同。
超时设置需要全面考虑。除了连接超时,还有查询超时和事务超时。setQueryTimeout()可以防止慢查询拖垮整个系统。我们遇到过因为没有设置查询超时,一个复杂报表查询运行了半小时,期间占用着数据库连接,影响其他业务。
数据类型映射也要小心。数据库的DATETIME映射到Java的java.sql.Timestamp,如果误用java.util.Date可能会丢失毫秒信息。布尔类型在不同数据库中表现不同,MySQL用TINYINT(1),Oracle用NUMBER(1),这些细节在跨数据库迁移时特别需要注意。
4.1 JDBC与新一代数据库技术融合趋势
传统关系型数据库依然重要,但云原生数据库、时序数据库、图数据库正在崛起。JDBC作为Java访问数据库的标准接口,也在适应这些变化。我最近接触的一个物联网项目,就同时使用了MySQL和时序数据库TDengine。
云数据库厂商普遍提供兼容JDBC的驱动。阿里云的PolarDB、亚马逊的Aurora,都能通过标准JDBC连接。这种兼容性保护了现有代码投资,迁移成本大大降低。不过云数据库的某些高级功能,可能需要调用特定的SDK,不完全通过JDBC暴露。
图数据库的JDBC支持还在完善中。Neo4j提供了JDBC驱动,但使用方式与传统SQL数据库差异很大。查询语言是Cypher而不是SQL,结果集处理也需要适应。这种差异提醒我们,JDBC标准在应对非关系型数据时存在局限性。
4.2 微服务架构下的数据访问层设计
微服务架构中,每个服务独立管理自己的数据库。JDBC的使用场景发生了变化,不再是单一的集中式数据访问。我参与的一个微服务改造项目,将原来的单体应用拆分成十几个服务,每个服务都有自己的数据源。
连接池配置需要重新考虑。单体应用通常配置一个大的连接池,微服务架构下每个服务需要独立的连接池。HikariCP因为轻量高性能,成为微服务场景的首选。但要注意连接数规划,避免所有服务连接数总和超过数据库最大连接限制。
分布式事务是个挑战。传统的JDBC事务只能管理单个数据源,跨服务的业务操作需要分布式事务方案。我们最终选择了最终一致性,通过消息队列和补偿机制保证数据最终一致。这种方案虽然复杂,但避免了分布式事务的性能瓶颈。
数据分片在微服务中很常见。用户数据按地域分片,订单数据按时间分片。JDBC需要配合分片中间件使用,如ShardingSphere。开发人员几乎无感知,仍然使用标准JDBC API,但背后已经是多个物理数据库在协同工作。
4.3 Java优学网JDBC教程学习路线建议
学习JDBC应该循序渐进。很多初学者直接跳到框架学习,忽略了JDBC基础。我教过的学生中,那些先扎实掌握JDBC的人,后期理解MyBatis、Hibernate时明显更轻松。
第一阶段掌握核心API。Connection、Statement、PreparedStatement、ResultSet,这四个接口要熟练使用。特别是PreparedStatement,能防止SQL注入,性能也更好。批处理、事务控制这些基础功能必须亲手编码实践。
第二阶段学习性能优化。连接池原理、SQL调优、索引设计。我们的教程提供了真实的慢查询日志,让学员分析执行计划,找出性能瓶颈。这种实战训练比单纯看书有效得多。
第三阶段接触企业级实践。分布式环境下的数据访问、多数据源配置、读写分离。我们模拟了电商促销场景,让学员体验高并发下的数据库压力,实践各种优化方案。
4.4 职业发展路径与技能提升策略
JDBC是Java后端开发的基石技能。即使现在流行ORM框架,理解JDBC原理仍然很重要。面试时经常被问到MyBatis和JDBC的关系,有底层经验的候选人明显更有优势。
技术深度决定发展上限。只会简单CRUD的程序员竞争力有限。深入理解数据库连接原理、事务隔离级别、锁机制,这些知识在解决复杂业务问题时非常有用。我们建议学员不仅要会用API,还要读一些开源连接池的源码。
横向扩展同样重要。除了JDBC,还应该学习NoSQL、消息队列、缓存技术。现代应用很少只依赖一种数据存储技术。我们的进阶课程包含了Redis、MongoDB与JDBC的配合使用,让学员理解不同数据存储的适用场景。
持续学习很关键。数据库技术发展很快,新的优化器特性、新的数据类型不断出现。订阅数据库厂商的技术博客,参与开源社区讨论,保持技术敏感度。也许明年就会有新的JDBC特性需要学习,技术人的成长永无止境。