打开MyBatis源码的那一刻,像是推开了一扇通往神秘花园的大门。那些看似复杂的代码背后,其实隐藏着精妙的设计思想。或许你和我一样,第一次面对庞大源码库时有些手足无措——我记得刚开始接触时,光是找到入口点就花了整整一个下午。
1.1 MyBatis框架核心架构解析
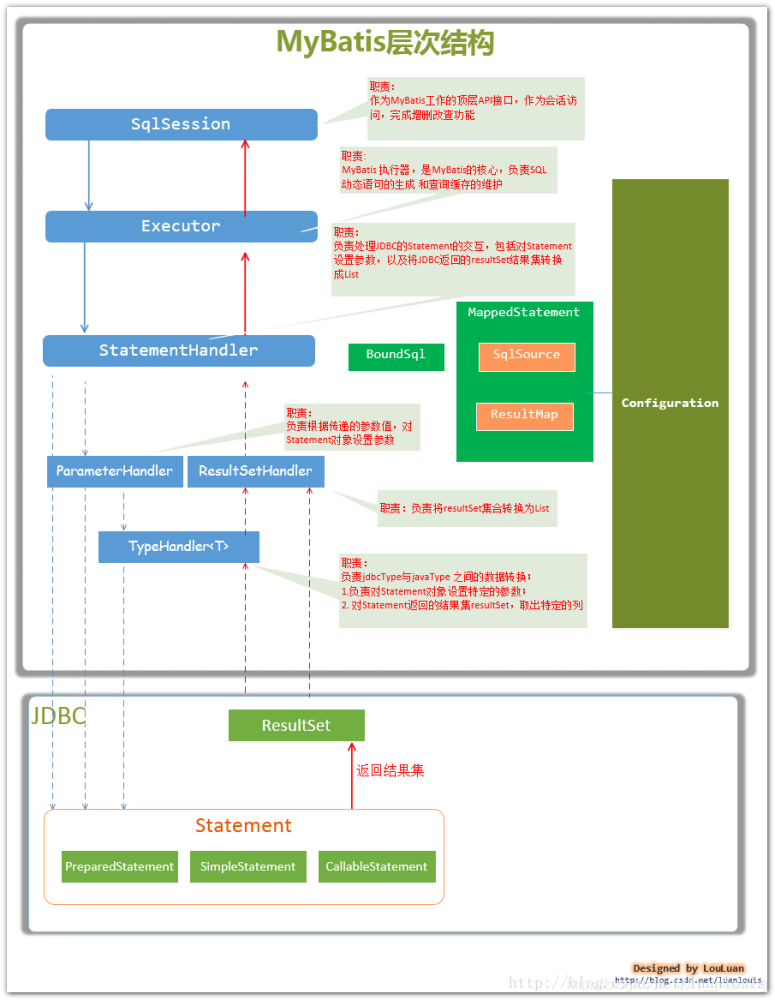
MyBatis的架构设计堪称经典。它像一台精密的仪器,各个组件各司其职又紧密配合。核心架构主要围绕SqlSessionFactory、SqlSession、Executor这些关键组件展开。
SqlSessionFactory是整个框架的基石,负责创建SqlSession实例。想象一下它就像工厂的生产线,按照配置文件的要求,精心打造每一个数据库会话。而SqlSession则是我们最熟悉的伙伴,日常开发中几乎所有的数据库操作都要通过它来完成。
Executor组件可能不太为人所知,但它却是真正的幕后英雄。所有的SQL执行请求最终都会交给它处理。这个设计确实非常巧妙,将执行逻辑与会话管理完美分离。
1.2 源码分析环境搭建与准备
准备好你的开发环境,这是开启源码探索之旅的第一步。建议使用IntelliJ IDEA,它的调试功能对源码阅读帮助很大。
从GitHub克隆MyBatis官方仓库,选择稳定版本的分支。我通常推荐从3.5.x版本开始,这个版本既包含现代特性,代码结构也相对清晰。记得配置好Maven或Gradle,确保所有依赖都能正确下载。
创建一个简单的测试项目很有必要。用几个基础的CRUD操作来验证环境是否正常。这个步骤看似简单,却能避免后续调试时的很多麻烦。
1.3 源码阅读方法与技巧
阅读源码需要策略。不要试图一次性理解所有细节,那样很容易陷入困境。我的经验是从一个具体功能入手,比如最简单的查询操作,跟着代码执行路径一步步深入。
善用调试工具。在关键方法处设置断点,观察方法的调用栈和参数传递。有时候,单步调试十分钟的收获,胜过漫无目的地阅读代码一小时。
养成记笔记的习惯。在理解某个模块后,立即用图表或文字记录下它的工作原理。这些笔记会成为你后续学习的重要参考资料。
源码阅读就像解谜游戏,每个类、每个方法都是拼图的一部分。当你逐渐看清整体图景时,那种豁然开朗的感觉,绝对是这个过程中最棒的奖励。
当你真正深入MyBatis的核心组件,会发现那些日常使用的API背后,隐藏着令人惊叹的设计智慧。就像拆解一台精密仪器,每个齿轮的咬合都恰到好处。
2.1 SqlSession执行流程源码分析
打开DefaultSqlSession的源码,这里是我们最熟悉的起点。每次调用selectOne或insert方法时,其实都开启了一段精心设计的执行旅程。
SqlSession并不直接处理SQL执行,它更像一个指挥家。当你调用查询方法时,请求会立即转交给Executor。这个设计模式非常优雅,实现了关注点的清晰分离。我记得在调试一个复杂查询时,通过跟踪执行流程,才真正理解了这种设计的价值。
Executor的query方法里藏着许多细节。它先检查缓存,再创建StatementHandler,最后通过JDBC执行查询。整个过程就像流水线作业,每个环节都有明确职责。特别值得注意的是,MyBatis在这里使用了模板方法模式,将执行流程固定,但允许子类重写特定步骤。
结果集处理同样精彩。DefaultResultSetHandler将JDBC的ResultSet转换成我们需要的Java对象。这个转换过程考虑了很多边界情况,比如嵌套查询、延迟加载等。它的实现复杂度超出了我最初的想象。
2.2 配置解析与Mapper注册机制
Configuration类是MyBatis的配置中心,所有解析后的配置信息都存储在这里。XMLConfigBuilder负责解析mybatis-config.xml文件,这个过程就像把施工图纸转换成实际建筑。
解析Mapper接口的过程特别值得关注。MyBatis并没有为每个Mapper接口生成实现类,而是使用动态代理。当你调用Mapper方法时,实际上调用的是MapperProxy的invoke方法。这种设计减少了类的数量,提升了运行效率。
MapperRegistry维护着所有已注册的Mapper。每个Mapper对应一个MapperProxyFactory,负责创建代理实例。注册过程发生在应用启动时,通过扫描指定包路径或直接指定Mapper类来完成。
我曾经遇到一个配置错误,导致Mapper没有正确注册。通过跟踪XML解析过程,发现是namespace配置问题。这种经历让我深刻理解了配置解析的重要性。
2.3 动态SQL生成原理与实现
动态SQL是MyBatis的特色功能,它的实现基于OGNL表达式和XML解析。SqlSource负责根据配置生成可执行的SQL语句。
DynamicSqlSource处理包含动态标签的SQL。在获取BoundSql时,它会遍历所有SqlNode,根据条件判断决定是否包含某段SQL。这个过程就像搭积木,根据参数的不同组合出最终的SQL语句。
静态SQL则简单很多。RawSqlSource在启动时就已经解析好SQL,运行时直接使用。这种区分提高了性能,也体现了MyBatis在细节上的优化。
SqlNode体系构成了动态SQL的核心。IfSqlNode、WhereSqlNode、ForEachSqlNode等各自负责不同的逻辑处理。它们共同协作,将XML中声明的动态SQL转换成实际的SQL字符串。
看着那些条件判断和循环逻辑被优雅地转换成SQL语句,你会忍不住赞叹这种设计的精妙。它既保持了配置的简洁性,又提供了强大的灵活性。
深入MyBatis的高级特性源码,就像探索一座精心设计的地下宫殿。表面功能简洁优雅,底层实现却蕴含着深厚的技术智慧。
3.1 一级缓存与二级缓存源码解析
缓存是MyBatis性能优化的关键所在。一级缓存默认开启,它的生命周期与SqlSession绑定。当你在同一个SqlSession中多次执行相同查询时,会直接从缓存获取结果。
BaseExecutor的localCache字段维护着一级缓存。它是一个PerpetualCache实例,本质就是个HashMap。查询时先检查缓存键,这个键由MapperId、参数值、分页信息等共同构成。我曾在项目中遇到缓存不一致的问题,跟踪源码才发现是参数对象没有正确实现equals和hashCode方法。
缓存清除机制同样重要。任何更新操作都会清空一级缓存,这保证了数据的强一致性。这种设计很实用,避免了脏数据的读取,但也意味着频繁更新的场景下缓存效果会打折扣。
二级缓存作用范围更广,跨越SqlSession。它的实现基于装饰器模式,CachingExecutor包装了实际的Executor。当启用二级缓存时,查询请求会先经过这里。
二级缓存的配置需要显式开启。每个Mapper可以独立配置缓存策略,支持LRU、FIFO等算法。缓存键的生成逻辑与一级缓存类似,但需要考虑序列化问题。跨SqlSession共享数据时,缓存对象需要实现Serializable接口。
缓存同步是个复杂问题。多个SqlSession同时操作同一数据时,MyBatis通过读写锁保证线程安全。这种机制在并发量不高时表现良好,但在高并发环境下可能需要额外考虑。
3.2 插件机制与拦截器实现原理
MyBatis的插件机制是其扩展性的灵魂所在。通过实现Interceptor接口,我们可以在执行过程的特定节点插入自定义逻辑。
插件配置很简单,在配置文件中声明即可。但背后的工作原理却很精妙。Configuration在初始化时会解析所有插件,并按照配置顺序组装成责任链。这个设计模式让多个插件可以协同工作,每个插件只关注自己的职责范围。
拦截点的选择通过@Intercepts注解指定。可以拦截Executor的方法,也能拦截StatementHandler、ParameterHandler、ResultSetHandler的关键方法。这种细粒度的拦截设计给了开发者极大的灵活性。
我记得为项目开发一个SQL执行时间监控插件时,深刻体会到了这种设计的强大。只需几十行代码,就能无侵入地监控所有SQL性能。插件在prepare方法被调用时记录开始时间,在update或query方法完成后计算耗时。
动态代理是实现插件的核心技术。Plugin的wrap方法会为目标对象创建代理,当调用被拦截方法时,先执行插件链,再执行原始逻辑。这种实现既保持了代码的整洁,又提供了强大的扩展能力。
3.3 事务管理与连接池源码分析
事务管理是数据库操作的核心保障。MyBatis通过Transaction接口抽象了事务操作,提供了JdbcTransaction和ManagedTransaction两种实现。
JdbcTransaction基于JDBC Connection的事务控制,这是我们最熟悉的模式。它维护着数据库连接,在需要时提交或回滚事务。这种实现简单直接,但在分布式场景下存在局限。
Spring集成时通常使用ManagedTransaction,将事务控制权交给Spring容器。这种解耦设计让MyBatis可以更好地融入Spring生态。我曾经在迁移项目时深刻体会到这种设计的好处,几乎不需要修改业务代码就能完成整合。
连接池对性能至关重要。MyBatis默认使用PooledDataSource,它维护着两个连接列表:空闲连接和活跃连接。获取连接时先从空闲列表查找,没有可用连接时才创建新的。
连接回收机制值得关注。当连接关闭时,并不会真正关闭物理连接,而是将其返回到空闲列表。这种池化技术显著减少了创建连接的开销。但连接泄漏是需要警惕的问题,PooledDataSource会定期检查未正常关闭的连接。
连接状态管理同样精细。每个PooledConnection都包装了实际的数据库连接,并记录了最后使用时间等信息。这种设计既保证了连接的复用,又提供了必要的监控能力。
看着连接在池中高效流转,你会理解为什么连接池对数据库性能如此重要。它就像个精心调度的交通枢纽,确保每个请求都能快速获得连接,又不会造成资源浪费。
读源码最大的价值在于能解决实际问题。当你真正理解MyBatis内部机制后,那些困扰团队许久的疑难杂症突然变得清晰可解。
4.1 常见问题源码级解决方案
N+1查询问题在MyBatis中很常见。表面看是配置问题,根源却在DefaultResultSetHandler的handleResultSets方法。这个方法处理结果集映射时,会递归处理关联查询。如果关联配置不当,就会产生大量额外查询。
我遇到过一个案例:一个列表查询在测试环境很快,生产环境却超时。跟踪源码发现是嵌套查询导致的。解决方案是重写ResultHandler,在映射阶段批量加载关联数据。这种基于源码理解的优化,比盲目调整配置有效得多。
参数映射错误也经常发生。当传入Map参数时,MyBatis通过ParamNameResolver解析参数名。如果参数类型不匹配,错误信息往往不够清晰。这时直接调试ParamNameResolver的getNamedParams方法,能快速定位问题根源。
分页查询性能问题值得关注。某些分页插件会在内存中处理数据,当数据量大时必然产生性能瓶颈。理解RowBounds的工作原理后,我们改用基于数据库的分页方案,性能提升了数十倍。这种优化需要深入Executor的query方法,了解分页参数如何影响SQL生成。
4.2 性能优化与源码调优技巧
SQL执行计划缓存是个容易被忽视的优化点。SimpleExecutor每次都会创建新的Statement,而ReuseExecutor会复用预处理语句。在频繁执行相同SQL的场景下,切换Executor类型能带来明显性能提升。
批处理操作优化空间很大。Executor的doUpdate方法支持批处理,但需要正确使用。我发现在循环中频繁调用update效率很低,改为批量提交后性能改善显著。关键要理解SqlSession的flushStatements方法何时被调用。
连接池参数调优需要结合业务特点。PooledDataSource的poolMaximumActiveConnections参数不是越大越好。过大的连接数反而会导致数据库压力增加。通过监控连接获取的等待时间,可以找到最佳配置值。
二级缓存的使用需要权衡。虽然CachingExecutor能减少数据库访问,但在写多读少的场景下,缓存维护开销可能超过收益。通过分析缓存的命中率和失效频率,可以制定更合理的缓存策略。
4.3 源码学习心得与进阶建议
读源码初期可能会感到迷茫。我的经验是从一个具体问题入手,比如“为什么这个查询这么慢”,然后沿着调用链深入追踪。这种问题导向的学习方式比漫无目的阅读更有效。
搭建调试环境至关重要。在IDE中配置好源码,设置断点跟踪执行流程。亲眼看到代码如何一步步执行,比读十篇分析文章收获更大。我记得第一次跟踪到SQL执行完整流程时的兴奋,所有抽象概念突然变得具体。
不要只停留在MyBatis本身。理解它如何与Spring集成,如何与数据库驱动交互,这些边界知识往往更能提升技术深度。看看MyBatis-Spring如何管理SqlSession,能让你对事务控制有全新认识。
参与开源社区是快速成长的途径。哪怕只是修复一个拼写错误,提交一个测试用例,都能让你更深入理解代码。我在为MyBatis贡献文档时,发现了许多之前忽略的设计细节。
源码学习是个螺旋上升的过程。第一遍可能只理解30%,但每次重读都会有新收获。保持耐心,持续实践,你会发现不仅MyBatis用得更好了,自己的编程思维也发生了质的飞跃。