配置环节往往是MyBatis使用过程中最容易出错的阶段。记得我第一次接触MyBatis时,花了整整一个下午才找到那个隐藏在配置文件里的路径错误。这种经历让我深刻理解到,正确的配置是框架稳定运行的基石。
1.1 数据源配置错误的常见表现及修复方法
数据源配置出错时,应用启动阶段就会暴露问题。控制台通常会出现"Could not get JDBC Connection"或"Failed to obtain JDBC Connection"这类异常信息。
一个典型场景是数据库连接参数填写错误。比如将端口号3306误写成3307,或者数据库名称拼写有误。我见过一个案例,开发人员将"test_db"写成了"test_db1",导致应用始终无法连接到数据库。
密码加密也是常见问题源。有些团队会在配置文件中使用加密后的数据库密码,但忘记配置对应的解密器。这种情况下,MyBatis会尝试用明文密码去连接,自然无法通过数据库的验证。
修复这些错误需要系统性的检查。先确认数据库服务是否正常运行,再逐项核对连接参数。密码加密问题则需要检查是否配置了正确的密码解密插件。有时候,简单的连接超时参数调整就能解决问题,比如将默认的30秒超时适当延长。
1.2 映射文件路径配置错误的排查技巧
映射文件路径配置错误相当隐蔽,往往在运行时才会暴露。症状包括"Invalid bound statement (not found)"异常,或者查询方法执行时抛出找不到对应SQL语句的错误。
在XML配置方式下,mapperLocations的配置特别容易出错。我习惯使用classpath:前缀来确保能够扫描到所有jar包中的映射文件。但要注意,classpath:在部分环境下可能存在性能问题。
基于注解的配置同样存在路径陷阱。使用@MapperScan注解时,如果basePackages参数设置不当,可能导致某些Mapper接口没有被正确扫描注册。这种情况下的错误信息往往不够明确,增加了排查难度。
一个实用的排查技巧是启用MyBatis的日志输出。将日志级别调到DEBUG,可以清楚地看到框架在启动时加载了哪些映射文件。如果预期的文件没有出现在日志中,基本可以确定是路径配置问题。
1.3 类型别名配置不当导致的异常处理
类型别名让映射配置更加简洁,但配置不当会引发各种类型转换异常。常见的错误信息包括"Type alias not found"或者"Cannot convert string to date"这类提示。
包扫描配置错误是最常见的诱因。在mybatis-config.xml中配置typeAliases时,如果package名称写错,框架就无法为对应的实体类注册别名。这种情况下,在映射文件中使用别名时会直接报错。
我建议在开发阶段尽量避免过度依赖别名。直接使用全限定类名虽然代码稍长,但能减少配置错误。等到项目稳定后,再考虑引入别名来提升可读性。
另一个容易忽略的问题是别名冲突。当两个不同包中的类具有相同名称时,后注册的别名会覆盖先注册的。这种问题很难发现,因为编译不会报错,只有在运行时才会出现类型不匹配的异常。
处理类型别名异常时,可以临时关闭别名功能,改用全类名进行测试。如果问题消失,就能确定是别名配置的问题。这种方法虽然原始,但往往能快速定位问题根源。
SQL映射文件就像是MyBatis的心脏,所有的数据操作都在这里定义。但这里也是最容易藏匿bug的地方。我曾经接手过一个项目,因为一个映射文件中的参数绑定错误,导致整个查询模块性能下降了70%。这种教训让我对SQL映射文件的编写格外谨慎。
2.1 参数绑定错误的诊断与解决
参数绑定错误通常表现为查询结果异常或者直接抛出绑定异常。控制台可能会出现"Parameter 'xxx' not found"这样的错误信息,让人一头雾水。
一个常见的陷阱是使用#{}和${}的混淆。#{}会进行预编译,能有效防止SQL注入,而${}直接进行字符串替换。我记得有个同事在模糊查询时错误使用了#{},结果查询条件完全失效。正确的做法应该是使用${}配合concat函数,或者直接使用MyBatis提供的bind标签。
参数名称不匹配也是高频错误。在接口方法中定义了@Param("userName"),但在XML中却写成了#{username},这种大小写或者拼写的细微差别就足以让参数绑定失败。现在我会习惯性地使用IDE的搜索功能,确保参数名称完全一致。
处理复杂对象时,属性路径的引用特别容易出错。比如要获取user对象的address属性的city属性,应该写成#{user.address.city}。如果漏掉了中间的address,直接写成#{user.city},MyBatis就无法正确解析这个路径。
2.2 结果映射配置不当的问题修复
结果映射配置错误往往更加隐蔽,因为程序可能不会直接报错,而是返回错误的数据。字段值错位、类型转换异常、关联对象为空,这些都是结果映射问题的典型表现。
字段名不匹配是最基础的问题。数据库列名是user_name,但结果映射中写成了username,MyBatis就无法自动映射这个字段。我一般会开启mapUnderscoreToCamelCase配置,让框架自动完成下划线到驼峰的转换,减少很多手动映射的工作。
关联映射的配置需要格外小心。在配置一对多关系时,如果忘记配置collection标签,或者嵌套的resultMap引用错误,关联对象列表就会始终为空。这种问题在单元测试中很容易被发现,但在集成测试阶段才发现就为时已晚。
类型处理器配置不当会导致各种奇怪的现象。日期字段被映射成时间戳字符串,枚举值变成了序号数字。我建议为每个自定义类型都显式配置类型处理器,虽然工作量稍大,但能避免很多意想不到的问题。
2.3 动态SQL语句编写中的陷阱及规避方法
动态SQL让MyBatis变得强大,但也引入了复杂性。if标签的滥用、foreach循环的性能问题、choose-when的逻辑错误,这些都是动态SQL中常见的坑。
if标签中的判断条件需要特别注意。我见过一个案例,开发者在if标签中直接判断字符串是否为空:test="name != null and name != ''"。这看起来没问题,但当name为"0"时,条件判断为false,导致查询结果不符合预期。正确的做法应该是使用更精确的判断条件。
foreach标签在处理大量数据时可能成为性能瓶颈。一次性传入上千个ID进行IN查询,不仅SQL语句超长,数据库解析起来也很吃力。我通常会对传入的集合大小做限制,超过一定数量就改用其他查询方式。
choose-when-otherwise结构的逻辑分支要确保互斥。如果多个when条件同时满足,只有第一个匹配的条件会生效。这种特性在某些场景下很有用,但如果设计不当,可能导致预期的分支永远无法执行。
动态SQL的调试比较困难,我习惯在开发阶段开启MyBatis的日志,直接查看最终生成的SQL语句。有时候你以为的SQL和实际执行的SQL可能相差甚远,这种差距往往就是问题的根源所在。
事务管理是MyBatis应用中那道看不见的防线。它默默守护着数据的一致性,但一旦出现问题,往往会造成灾难性的后果。我曾参与排查过一个电商系统的bug,用户下单后库存扣减了,订单却没生成。追根溯源才发现是事务配置出了问题,这种数据不一致的状况持续了整整一周才被发现。
3.1 事务未生效的常见原因分析
事务未生效的表现很微妙——数据操作看起来都执行成功了,但遇到异常时该回滚的没回滚,该提交的也没提交。这种问题就像温水煮青蛙,等到发现时往往已经造成了数据污染。
自动提交模式是第一个要检查的地方。在独立的MyBatis使用中,如果没有显式开启事务,默认就是自动提交。这意味着每个SQL语句都会立即提交,根本不会等待整个事务边界。我记得有个新手开发者抱怨事务不生效,最后发现他根本没调用SqlSession的commit方法。
Spring集成环境中的@Transactional注解失效更常见。注解标注的方法必须是public的,而且要通过代理对象调用。如果直接在类内部调用带@Transactional的方法,注解就会被绕过。这种自调用问题困扰过很多开发者,包括当年的我。
事务管理器的配置错误也会导致事务失效。在Spring配置中声明了多个事务管理器,但没有指定默认的,或者@Transactional注解中没有明确指定使用哪个事务管理器。这种情况下,Spring可能根本找不到合适的事务管理器来管理事务。
3.2 事务传播行为配置错误解析
事务传播行为决定了方法之间如何协调事务边界。配置错误不会立即报错,但会导致事务边界混乱,出现事务嵌套、事务挂起等意料之外的行为。
REQUIRED和REQUIRES_NEW的混淆是最典型的错误。REQUIRED会让方法加入当前事务,而REQUIRES_NEW会挂起当前事务并开启新事务。我处理过一个财务系统的问题,内层方法配置了REQUIRES_NEW,本意是独立提交,结果外层事务回滚时把内层也回滚了,因为数据库不支持嵌套事务。
SUPPORTS和NOT_SUPPORTED的使用场景需要仔细考量。SUPPORTS会在有事务时加入事务,没有事务时非事务执行。这种灵活性的另一面是不确定性——你永远无法确定当前操作是否在事务中。对于要求强一致性的操作,这种传播行为显然不合适。
编程式事务管理中的传播行为配置更容易出错。在使用TransactionTemplate时,如果没正确设置传播行为属性,默认的PROPAGATION_REQUIRED可能不符合业务需求。特别是那些需要独立事务的日志记录、消息发送等操作,必须显式指定传播行为。
3.3 事务回滚失败的排查步骤
事务回滚失败是最让人头疼的问题之一。你以为异常发生时数据会回滚,实际上它们却被持久化了。这种状况下的数据修复往往需要手动干预,成本极高。
异常类型不匹配是回滚失败的常见原因。Spring默认只对RuntimeException和Error进行回滚,受检异常不会触发回滚。如果你在@Transactional中没指定rollbackFor,而业务又抛出了受检异常,事务就会正常提交。我建议明确指定rollbackFor,或者统一使用运行时异常。
数据库连接泄漏会导致回滚失效。如果事务进行中发生了连接泄漏,连接池中的连接可能一直处于未提交状态。后续操作复用这个连接时,可能会看到其他事务的未提交数据,或者回滚操作根本影响不到这个连接上的更改。
部分回滚的情况特别棘手。在分布式事务或者多个数据源的环境中,可能只有部分操作成功回滚。我遇到过一个多数据源配置,主数据源回滚成功,但从数据源因为连接超时没能回滚。这种部分成功部分失败的状态修复起来异常困难。
事务超时设置不当也会影响回滚。如果事务执行时间超过超时设置,数据库可能自动回滚,但应用层可能还在等待响应。这种超时回滚与应用层回滚的竞态条件很难调试,需要结合数据库日志和应用日志综合分析。
缓存就像程序世界的记忆系统,它能显著提升性能,但记忆出错时带来的困扰往往比没有记忆更严重。我维护过一个内容管理系统,因为缓存配置问题,用户发布新文章后前台仍然显示旧内容。这种“时空错乱”持续了三天,直到有用户投诉才发现问题。缓存失效的代价有时候比我们想象的要大得多。
4.1 一级缓存引发的问题及解决方案
MyBatis的一级缓存是SqlSession级别的,它在同一个会话中默默工作,很多时候开发者甚至意识不到它的存在。这种“透明”特性反而容易引发一些隐蔽的问题。
数据不一致是最典型的困扰。在同一个SqlSession中,如果你先执行查询,然后手动更新了数据库,再执行相同的查询,返回的仍然是缓存中的旧数据。我见过一个批量处理任务,在循环中先查询再更新,由于没有清空缓存,后续循环读取的都是最初的数据。这种问题在测试环境很难发现,因为测试数据量小,通常不会复用SqlSession。
SqlSession的生命周期管理不当会加剧一级缓存的问题。在Web应用中,如果把SqlSession绑定到请求范围,但请求处理过程中有多个线程操作同一个SqlSession,缓存就可能被意外污染。有个团队曾经因为把SqlSession存放到ThreadLocal中,导致用户间数据互相干扰。
清空缓发的时机选择很重要。手动调用sqlSession.clearCache()可以立即清空一级缓存,但什么时候调用需要仔细设计。过于频繁的清空会让缓存失去意义,而长期不清空又可能导致数据过期。我通常建议在写操作后主动清空相关缓存,或者在特定的业务边界处统一清理。
4.2 二级缓存配置错误的调试方法
二级缓存跨越SqlSession边界,配置复杂度明显增加。很多时候你以为缓存生效了,实际上它可能在某个环节被绕过。
缓存未命中的调试需要系统性的方法。先检查是否在映射文件中正确配置了
缓存范围和作用域的混淆很常见。在Spring集成环境中,如果没正确配置缓存的作用域,可能会出现每个SqlSessionFactory都有自己的缓存实例,无法共享。这种情况下,所谓的“二级缓存”实际上退化成了多个一级缓存。
缓存同步问题在集群环境中尤其突出。当应用部署在多台服务器上时,默认的二级缓存实现是进程内的,不同服务器间的缓存无法同步。我参与过一个电商项目的性能优化,开始时直接用默认配置,结果不同节点的商品库存缓存完全不一致。后来改用Redis等集中式缓存才解决这个问题。
缓存命中率的监控往往被忽视。通过开启MyBatis的日志输出,可以观察缓存的命中情况。如果发现缓存命中率异常低,可能是缓存键设计不合理,或者缓存范围设置过大导致内存压力,系统频繁淘汰缓存内容。
4.3 缓存击穿和缓存雪崩的预防策略
缓存击穿和雪崩听起来很学术,但本质上都是缓存失效时的连锁反应。预防这些问题的关键不在于技术有多复杂,而在于对缓存生命周期的精细控制。
缓存击穿通常发生在热点数据上。当某个热点key过期时,大量请求瞬间涌向数据库。我处理过一个明星离婚新闻的案例,缓存设置的过期时间相同,结果在某个整点时刻缓存集体失效,数据库连接池瞬间被打满。解决方案其实很简单——为不同的key设置随机的过期时间,避免集体失效。
缓存雪崩的破坏力更大。当大量缓存同时失效,或者缓存服务宕机时,所有请求直接落到数据库上。这种“雪崩效应”可能让整个系统崩溃。预防雪崩需要多层次的设计:本地缓存作为一级防线,分布式缓存作为二级防线,数据库层面还要有限流措施。
缓存预热是个值得投入的策略。对于已知的热点数据,在缓存过期前就主动更新,或者系统启动时预先加载。我们有个报表系统,每天凌晨定时预热当天可能访问的统计报表,有效避免了上班时间集中访问导致的缓存穿透。
降级和熔断机制是最后的保障。当检测到缓存异常或数据库压力过大时,系统应该有能力暂时关闭部分缓存功能,或者返回降级内容。这种“壮士断腕”的决策虽然会影响用户体验,但能保证核心服务的可用性。毕竟,显示稍旧的内容总比整个系统崩溃要好得多。
性能问题就像温水煮青蛙,往往在不知不觉中拖垮整个系统。我参与过一个用户量突然暴增的项目,初期运行流畅,随着数据量增长,某些页面加载时间从2秒延长到20秒。这种缓慢的恶化过程让团队很难及时警觉,直到用户开始大量流失才意识到问题的严重性。性能优化的价值不仅在于提升速度,更在于维持系统的可伸缩性。
5.1 N+1查询问题的识别与优化
N+1查询是ORM框架中最经典的性能陷阱。表面上看代码很简洁,实际上在背后执行了大量的数据库查询。这种问题在开发阶段很难察觉,因为测试数据量小,查询延迟不明显。
识别N+1问题需要敏锐的观察力。当你看到一个循环中嵌套着数据库查询时,警报就应该响起。我review过一个订单查询功能,代码先查询订单列表,然后遍历每个订单去查询关联的商品信息。100个订单就产生了101次数据库查询——1次查订单,100次查商品。这种查询模式在数据量小时相安无事,一旦订单量达到万级别,系统响应时间就呈指数级增长。
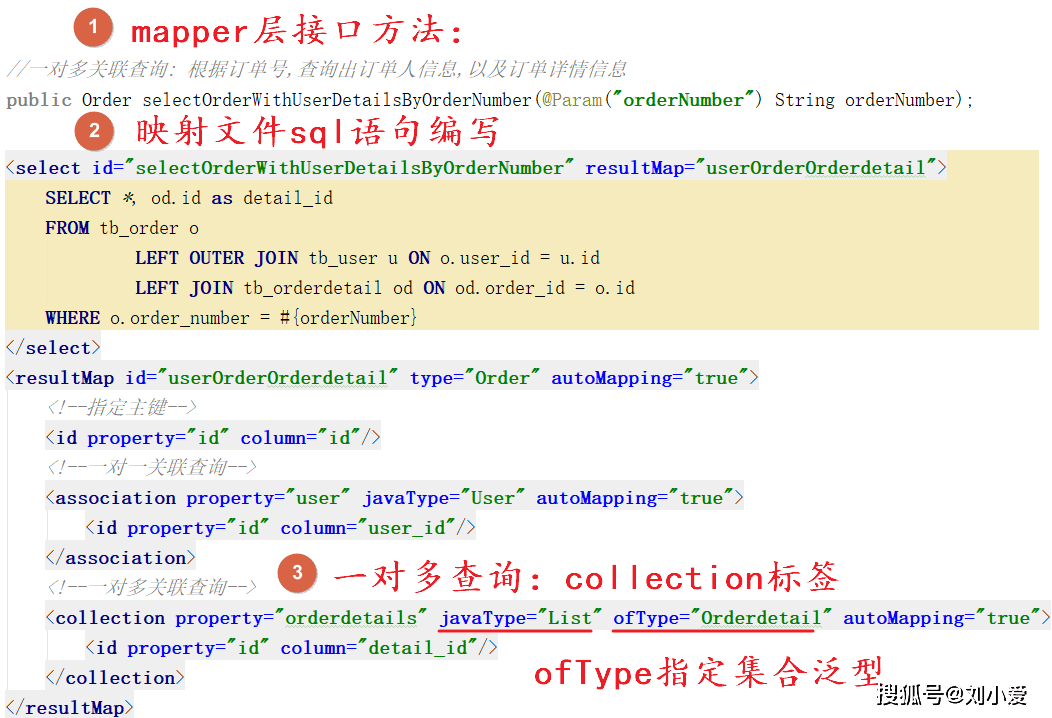
MyBatis提供了优雅的解决方案。通过使用关联查询或集合映射,可以在一次查询中获取所有需要的数据。比如在订单映射文件中配置
但关联查询不是万能药。当关联数据过多时,单次查询可能返回巨大的结果集,造成网络传输和内存分配的负担。我遇到过因为关联层级太深,一个查询返回了上百个字段,反而比N+1查询更慢的情况。这时候需要权衡:是接受多次查询的延迟,还是承受大结果集的处理开销。
5.2 懒加载配置错误的排查技巧
懒加载是个精妙的设计,它在需要时才加载关联数据,避免了一次性加载所有内容。但这个“聪明”的特性如果配置不当,可能引发更多问题。
典型的懒加载陷阱发生在Session关闭后。当你从数据库获取了一个实体,然后在Service层尝试访问其懒加载属性时,如果原始的SqlSession已经关闭,就会抛出LazyInitializationException。这种错误在分层架构中特别常见,因为通常会在DAO层关闭Session,等到Service层使用对象时才发现无法加载关联数据。
解决懒加载异常有多种思路。可以在View层之前保持Session开启,这就是Open Session in View模式。但这种方式要谨慎使用,过长的Session生命周期可能导致数据库连接占用太久。我倾向于在需要懒加载数据的业务方法中,显式地初始化必要的关联属性。比如调用Hibernate.initialize(order.getItems())来主动触发加载。
懒加载的配置粒度需要仔细考量。在映射文件中,你可以为每个关联关系单独设置fetchType="lazy"或fetchType="eager"。全局的懒加载策略可以在配置文件中设置,但容易被忽略。有个团队在配置文件中启用了全局懒加载,但某个业务场景需要立即加载所有关联数据,由于没注意到全局配置,导致产生了大量额外的查询。
性能监控可以帮助发现懒加载的误用。通过分析SQL日志,如果发现某个业务操作中出现了大量的小查询,很可能是不合理的懒加载导致的。我曾经优化过一个用户详情页面,原本需要17次查询才能渲染完整页面,调整懒加载策略后降到3次,页面加载时间减少了70%。
5.3 大数据量查询的性能调优方法
处理大数据量查询就像在沙漠中找一粒特定的沙子,方法不对就会事倍功半。传统的一次性加载所有数据的方式,在面对百万级记录时几乎肯定会引发内存溢出。
分页查询是必须掌握的基础技能。但很多开发者只记住了使用LIMIT,却忽略了排序字段的性能影响。我优化过一个分页功能,越往后翻页速度越慢,检查发现是因为没有为排序字段建立索引。当翻到第1000页时,数据库需要先扫描前面的999页数据,性能自然急剧下降。合适的索引加上正确的分页语句,能让翻页操作保持稳定的响应时间。
流式查询适合处理海量数据导出场景。与传统查询一次性加载所有结果到内存不同,流式查询允许逐条处理结果。MyBatis提供了ResultHandler接口来实现这个功能。我们有个数据导出需求需要处理百万行记录,改用流式查询后内存使用从2GB降到200MB左右。不过要注意,流式查询期间需要保持数据库连接,不适合在高并发场景中使用。
批量处理是另一个重要优化手段。对于需要处理大量数据的任务,将其拆分成多个小批次执行。我设计过一个用户标签更新任务,最初版本一次性更新所有用户,经常因为超时失败。改成每次处理1000个用户后,不仅成功率提升,还能更好地利用系统资源。
查询本身的优化往往被忽视。检查执行的SQL语句,避免使用SELECT *,只获取需要的字段。复杂的联表查询可以考虑拆分成多个简单查询,有时候在应用层做数据组装比在数据库层做复杂Join更高效。数据库的查询执行计划是个很好的分析工具,它能够揭示索引使用情况和潜在的性能瓶颈。
适当的超时设置能防止慢查询拖垮整个系统。我给每个重要查询都设置了合理的超时时间,当查询超过预定时间仍末返回结果时自动终止。这种防御性设计在生产环境中多次避免了因某个慢查询导致的连锁故障。
集成阶段就像组装精密仪器,每个零件都要严丝合缝。我记得有个项目在测试环境运行完美,部署到生产环境后却频繁报错。团队花了三天时间才发现是配置文件中的一个小小路径差异导致的。这种环境间的细微差别往往成为部署路上的隐形陷阱。集成部署考验的不仅是技术能力,更是对细节的掌控力。
6.1 Spring集成配置错误的解决方法
Spring与MyBatis的集成看似简单,配置项却暗藏玄机。最常见的错误往往出现在bean定义环节,特别是那些看似无关紧要的属性设置。
SqlSessionFactoryBean的配置需要格外细心。我遇到过数据源正确配置却无法建立数据库连接的情况,最终发现是mapperLocations路径使用了错误的通配符模式。Spring的资源解析器对ant风格路径的支持很完善,但一个小小的*号位置错误就可能导致所有映射文件加载失败。建议在日志级别设置为DEBUG时观察MyBatis的初始化过程,确认映射文件是否被正确识别。
事务管理器的配置是另一个重灾区。有次代码审查时发现,团队在Spring中配置了事务管理器,但Service方法上的@Transactional注解始终不生效。排查后发现是配置中缺少了<tx:annotation-driven/>标签。这个疏忽导致整个事务管控机制形同虚设,数据一致性完全得不到保障。
属性占位符的解析时机可能引发意想不到的问题。有个案例中,数据库连接参数在properties文件中定义正确,但MyBatis启动时却报连接失败。根本原因是属性占位符配置在Spring上下文加载之后才被解析。将property-placeholder配置移到上下文最前面就解决了问题。这种配置顺序的依赖性在文档中很少强调,却在实际部署中频繁出现。
集成测试能够有效预防配置错误。我习惯为每个数据访问层编写基础的集成测试用例,这些用例会在真实的Spring容器中运行,能够及时发现配置问题。一个简单的查询测试就能验证从数据源到映射文件的完整链路是否通畅。
6.2 多数据源配置中的常见陷阱
多数据源配置就像同时驾驭多匹马,协调不好就会人仰马翻。随着微服务架构的流行,单个应用连接多个数据库的场景越来越普遍。
数据源路由的配置需要精确定义。我参与过一个电商项目,需要同时连接用户库和商品库。初期配置中两个数据源的bean名称相似,导致Spring在自动装配时经常选错对象。后来我们采用了明确的命名规范:userDataSource和productDataSource,这种清晰的命名消除了注入时的歧义。
事务管理在多数据源环境下变得复杂。默认的事务管理器只能管理一个数据源,当业务需要跨库操作时,就需要引入分布式事务或采用最终一致性方案。有个支付系统最初尝试使用JTA管理多数据源事务,但因为性能开销太大不得不放弃。最终改用业务层面的补偿机制,虽然实现复杂些,但保证了系统的响应速度。
MyBatis的SqlSessionFactory需要与数据源一一对应。常见的错误是在多数据源环境下只配置一个SqlSessionFactory,然后期望它能自动识别不同的数据源。正确的做法是为每个数据源创建独立的SqlSessionFactory实例,并在DAO层明确指定使用哪个工厂。这种明确的绑定关系虽然增加了配置量,但避免了运行时的混乱。
动态数据源切换是更高级的需求。通过AOP和ThreadLocal可以实现运行时数据源的路由。我实现过一个多租户系统,根据请求中的租户标识自动切换到对应的数据库。这种方案的难点在于确保数据源切换的时机准确,特别是在事务边界内。有个隐蔽的bug是在事务开始后才切换数据源,导致整个事务在错误的数据源上执行。
连接池配置在不同数据源间可能需要差异化处理。主业务数据库连接池应该设置较大的最大连接数,而用于报表的只读数据库可以配置较小的连接池。忽略这种差异可能导致某些数据源连接耗尽,而其他数据源资源闲置的不均衡现象。
6.3 生产环境部署时的注意事项
生产环境就像战场,准备工作越充分,意外情况越少。从测试环境到生产环境的跨越往往伴随着配置、资源和流量的显著变化。
配置文件的环境隔离至关重要。我强烈建议使用Spring Profile来管理不同环境的配置。有个团队因为疏忽将测试环境的数据库配置打包到了生产部署包中,导致生产数据被意外修改。通过Profile机制,可以确保每个环境只加载对应的配置属性,这种隔离提供了基本的安全保障。
数据库连接的SSL加密在生产环境中不应被忽略。虽然开发测试环境可能使用明文连接,但生产环境必须启用SSL。我审计过一个系统,数据库连接因为没有加密导致敏感数据在传输过程中面临风险。启用SSL只需要在连接字符串中添加几个参数,这种简单的安全措施能有效防范中间人攻击。
连接池参数的调优需要基于实际负载。开发环境常用的默认配置在生产环境往往不够用。最大连接数、最小空闲连接、连接超时时间这些参数都需要根据预期的并发量进行调整。我通常会在系统上线初期设置相对保守的参数,然后根据监控数据逐步优化。
日志级别的调整是部署前的必要步骤。开发环境的DEBUG级别日志在生产环境会产生大量IO操作,影响系统性能。但也不能简单地全部关闭,需要保留足够的错误信息和关键业务流程日志。有个线上问题排查时发现关键日志被关闭,不得不临时修改日志级别重新部署,这种被动的调整增加了故障恢复时间。
健康检查机制的建立能提前发现问题。除了Spring Boot自带的actuator端点,我还习惯为关键数据源和外部服务依赖添加自定义健康检查。这些检查会在系统启动时和执行定时任务前自动运行,确保依赖服务可用。这种防御性设计帮助我们避免了很多因依赖服务异常导致的连锁故障。
监控和告警的配置同样重要。SQL执行时间、慢查询统计、连接池使用率这些指标都应该纳入监控范围。我设置了一个规则:任何SQL执行时间超过5秒就触发告警。这个简单的监控策略多次帮助我们及时发现性能退化问题,在用户感知到之前就完成优化。