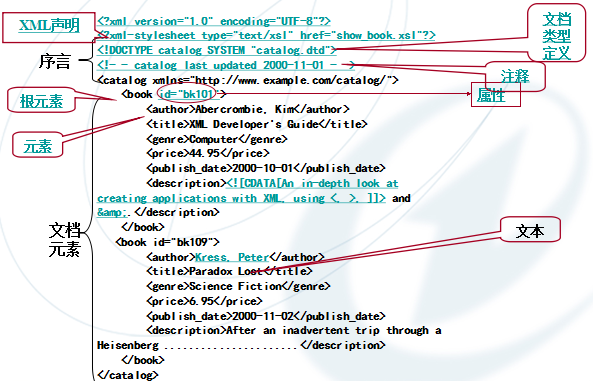
DOM解析就像给XML文档拍了一张全家福。XML文档中的每个元素、属性和文本都被捕捉成一个对象,整齐地排列在内存的树形结构里。想象一下打开家族相册,你能清晰地看到祖辈、父母、子女之间的层级关系,DOM解析也是类似的工作原理。
DOM解析的基本原理
XML文档被解析器完整地读入内存后,会构建出一棵节点树。每个标签变成一个元素节点,属性变成属性节点,文本内容变成文本节点。这些节点通过父子关系、兄弟关系相互连接,形成一个完整的文档对象模型。
我记得第一次接触DOM解析时,惊讶于它的直观性。你不需要逐行扫描文档,而是直接定位到感兴趣的节点进行操作。比如要修改某个商品的库存数量,直接找到对应的元素节点修改数值即可。
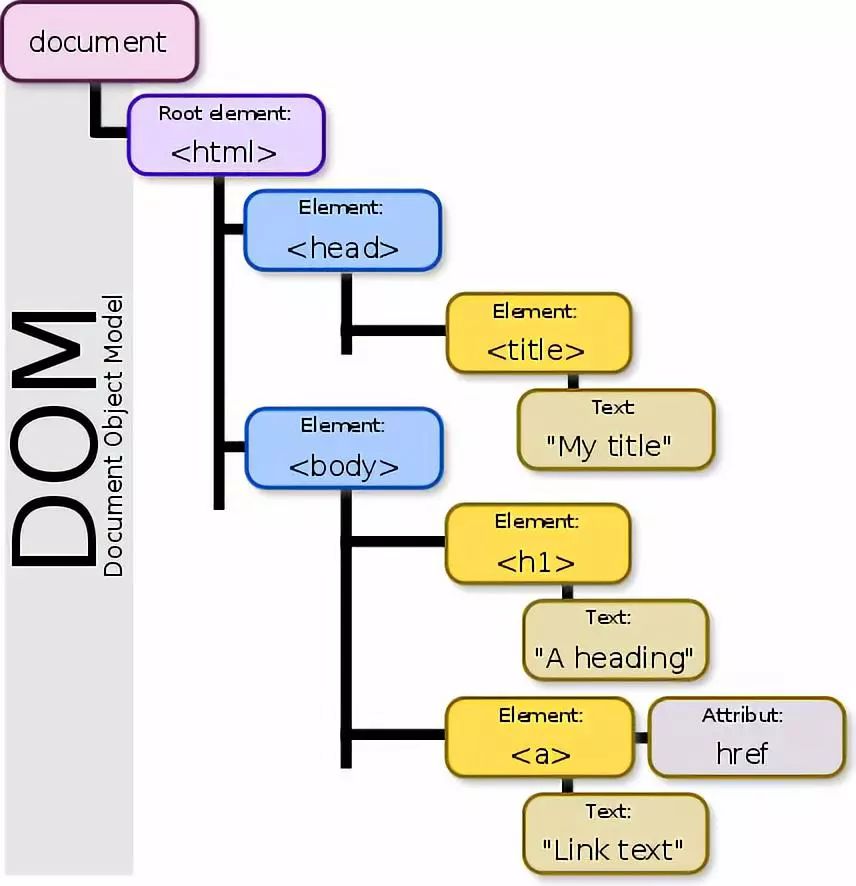
DOM树结构解析
DOM树就像现实中的家族树。文档元素是根节点,相当于家族的创始人。下面的子元素是直系后代,属性节点像是每个人的特征标签,文本节点则承载着具体内容。
根元素 ├── 子元素1 │ ├── 属性节点 │ └── 文本节点 └── 子元素2
├── 子元素2.1
└── 子元素2.2
这种层次结构让数据的组织和访问变得异常清晰。你可以轻松地找到某个节点的所有子节点,或者沿着父子关系向上追溯。
DOM解析的优势与适用场景
DOM解析特别适合需要频繁修改XML文档的场景。因为整个文档都在内存中,增删改查操作响应迅速。比如开发配置文件编辑器时,用户每次修改都能立即看到效果。
另一个优势是随机访问能力。不需要从头开始解析,可以直接跳转到任意节点进行操作。这在处理大型但结构复杂的文档时非常实用。
不过DOM解析会占用较多内存,特别是在处理超大XML文件时。这时候可能需要考虑其他解析方式。但在大多数企业级应用中,DOM解析的便利性往往更值得青睐。 import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document; import org.w3c.dom.Node; import org.w3c.dom.NodeList;
// 错误示例 String value = element.getElementsByTagName("nonexistent")
.item(0).getTextContent(); // 可能抛出NullPointerException
// 正确做法 NodeList nodes = element.getElementsByTagName("nonexistent"); if (nodes.getLength() > 0) {
String value = nodes.item(0).getTextContent();
} else {
System.out.println("节点不存在");
}