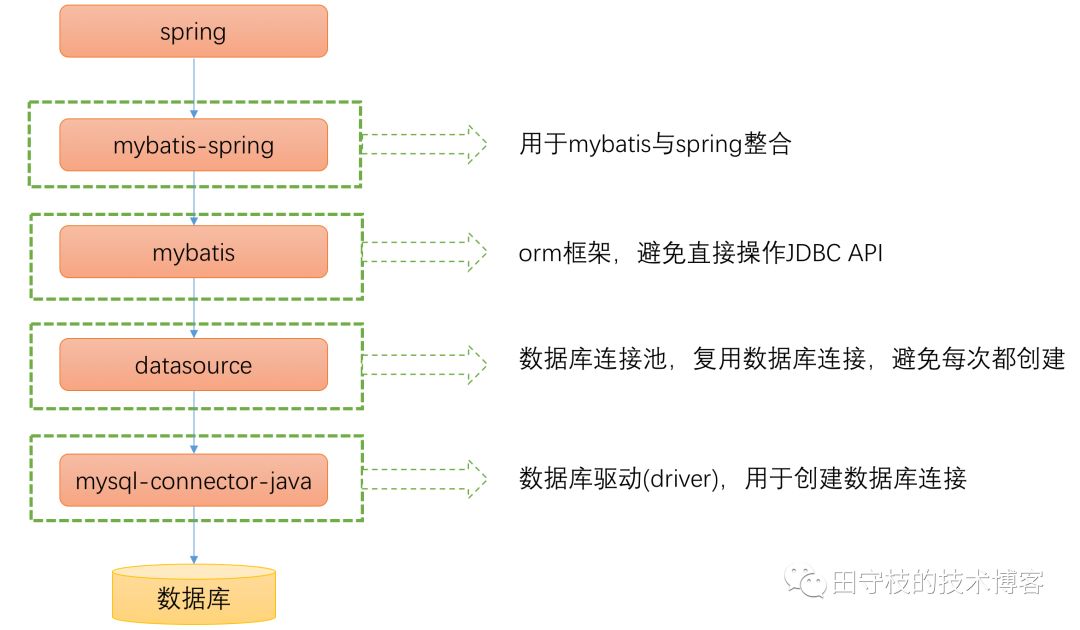
1.1 MyBatis框架核心特性分析
MyBatis像一位细心的翻译官,在Java对象和数据库之间架起沟通的桥梁。它最吸引人的地方在于那份恰到好处的灵活——既不像纯JDBC那样需要手动处理所有细节,也不像某些全自动ORM框架那样完全剥夺你对SQL的控制权。
SQL映射文件是MyBatis的灵魂所在。你可以把每条SQL语句都当作精心雕琢的艺术品,在XML文件中细细打磨。动态SQL功能尤其令人惊喜,那些<if>,<choose>,<foreach>标签让SQL语句变得生动起来。记得我第一次使用<foreach>处理批量插入时,原本需要几十行代码的逻辑,现在几行配置就轻松搞定。
参数映射和结果集映射是另一个亮点。你可以把查询结果自动填充到POJO对象,也能将复杂对象拆解成多个数据库字段。这种双向转换的能力,让数据在不同形态间自如流转。
1.2 Spring框架依赖注入机制
Spring的依赖注入像一场精心安排的舞会,每个组件都在正确的时间出现在正确的位置。控制反转(IoC)这个概念听起来有点抽象,但理解后会发现它让代码变得异常优雅。
容器管理着所有Bean的生命周期,从创建、装配到销毁。注解驱动的开发方式让配置变得简单,@Autowired、@Component这些注解像魔法标签,告诉Spring该如何处理你的类。XML配置虽然略显传统,但在复杂场景下依然有其不可替代的价值。
有次我接手一个老项目,看到满屏的new操作符和紧耦合的类关系,顿时理解了为什么Spring能成为企业级开发的事实标准。它让代码的每个部分都保持独立,却又能够完美协作。
1.3 整合的必要性与优势分析
单独使用MyBatis时,你需要手动管理SqlSession,处理事务,考虑连接关闭。这些重复性工作不仅枯燥,还容易出错。Spring的出现正好弥补了这些短板。
整合后的世界变得清爽很多。Spring接管了对象创建和依赖注入,MyBatis专注于数据访问。事务管理变得异常简单,一个@Transactional注解就能搞定原本需要大量模板代码的功能。
资源管理也更加优雅。数据库连接在使用完毕后自动归还连接池,不用担心资源泄漏。这种分工协作的模式,让两个框架都能发挥各自的专长。
性能优化也变得更容易。结合Spring的AOP,你可以轻松实现SQL执行时间监控、慢查询预警等功能。这种组合带来的协同效应,远大于简单叠加。
1.4 整合架构设计原理
整合的核心在于几个关键组件的巧妙配合。SqlSessionFactoryBean是第一个重要角色,它负责在Spring容器中创建MyBatis的SqlSessionFactory。这个工厂对象就像MyBatis的指挥中心,管理着所有数据库操作。
MapperScannerConfigurer是个聪明的设计,它会自动扫描指定包下的接口,并为它们创建代理实现。你不再需要为每个Mapper接口手动编写实现类,Spring和MyBatis会帮你完成这个魔法。
事务管理的整合尤为精妙。Spring的事务管理器与MyBatis的执行器紧密配合,确保在同一个事务中使用的是同一个数据库连接。这种透明化的处理,让开发者可以专注于业务逻辑。
数据源配置是基础中的基础。无论是简单的DBCP,还是更高效的HikariCP,都能与这套架构完美融合。这种设计上的包容性,让整合方案能够适应各种不同的应用场景。
2.1 项目依赖配置详解
打开pom.xml文件时,那些依赖项就像搭建房屋的地基。MyBatis-Spring桥接依赖必不可少,它是两个框架之间的粘合剂。我习惯先添加Spring核心依赖——spring-context提供IoC容器支持,spring-jdbc处理数据访问基础。
MyBatis核心依赖紧随其后,mybatis和mybatis-spring缺一不可。数据库驱动根据实际选择,MySQL还是PostgreSQL都有对应的驱动包。记得有次忘记添加mybatis-spring,整合过程处处碰壁,排查半天才发现少了这个关键组件。
日志依赖经常被忽略但很重要。Slf4j配合Logback能让你清楚看到MyBatis执行的每条SQL语句,这对调试非常有帮助。测试依赖也值得投入,spring-test和junit让集成测试变得简单。
版本匹配是个需要留心的细节。不同版本的MyBatis和Spring可能存在兼容性问题,选择经过验证的版本组合能避免很多麻烦。
2.2 数据源配置管理
数据源像数据库连接的管家,决定着应用如何与数据库建立联系。Spring提供了多种配置方式,基于XML的配置虽然略显传统,但在复杂场景下依然清晰明了。
使用HikariCP时,那些配置参数都有其特定含义。maximumPoolSize控制着连接池的大小,connectionTimeout设定等待连接的超时时间。有次线上环境连接数不足,适当调整maximumPoolSize后性能明显改善。
DBCP2是另一个可靠选择,它的配置项更加丰富。testOnBorrow能确保每次获取的连接都是有效的,避免使用已失效的数据库连接。这种预防措施在生产环境中特别重要。
基于JavaConfig的配置方式越来越流行。@Configuration注解标记配置类,@Bean方法返回数据源实例。代码提示和类型安全让配置过程更加顺畅,重构时也不容易出错。
2.3 MyBatis-Spring整合配置
SqlSessionFactoryBean是整合的核心枢纽。它在Spring容器中创建MyBatis的SqlSessionFactory,需要注入数据源和Mapper映射文件位置。configLocation属性可以指定MyBatis的主配置文件,那里可以配置插件、类型处理器等高级功能。
MapperScannerConfigurer的自动扫描功能很实用。设置basePackage属性后,它会扫描指定包下的所有Mapper接口并注册为Spring Bean。你再也不需要为每个接口编写实现类,这种自动化处理大大提升了开发效率。
我偏好将配置分散到多个文件。SQL映射文件按模块划分,保持每个文件的专注度。这种组织方式在大型项目中特别受用,不同开发者可以并行工作而不会产生冲突。
事务管理配置在这里初见端倪。虽然详细配置在后续章节,但基础的tx命名空间引入和注解驱动开启需要在此完成。@Transactional注解已经开始发挥作用,方法级别的事务控制变得触手可及。
2.4 事务管理配置
Spring的事务管理像一位细心的调度员,确保数据库操作要么全部成功,要么全部回滚。DataSourceTransactionManager是最常用的实现,它基于数据源管理事务边界。
@Transactional注解的配置选项很丰富。readOnly属性标记只读事务,数据库可能据此进行优化。propagation定义事务传播行为,REQUIRED表示如果当前存在事务就加入,否则新建一个。
隔离级别的选择需要谨慎。READ_COMMITTED能防止脏读,在大多数场景下已经足够。SERIALIZABLE提供最高隔离级别,但性能代价也最大。根据业务需求找到平衡点很重要。
记得有个电商项目,下单时需要同时更新库存、生成订单、扣除余额。如果没有事务保护,某个步骤失败可能导致数据不一致。@Transactional注解确保这些操作原子性执行,给业务逻辑提供了坚实保障。
异常回滚规则可以精细控制。默认情况下运行时异常触发回滚,受检异常不会。通过rollbackFor属性可以自定义回滚的异常类型,这种灵活性在处理复杂业务逻辑时很有价值。
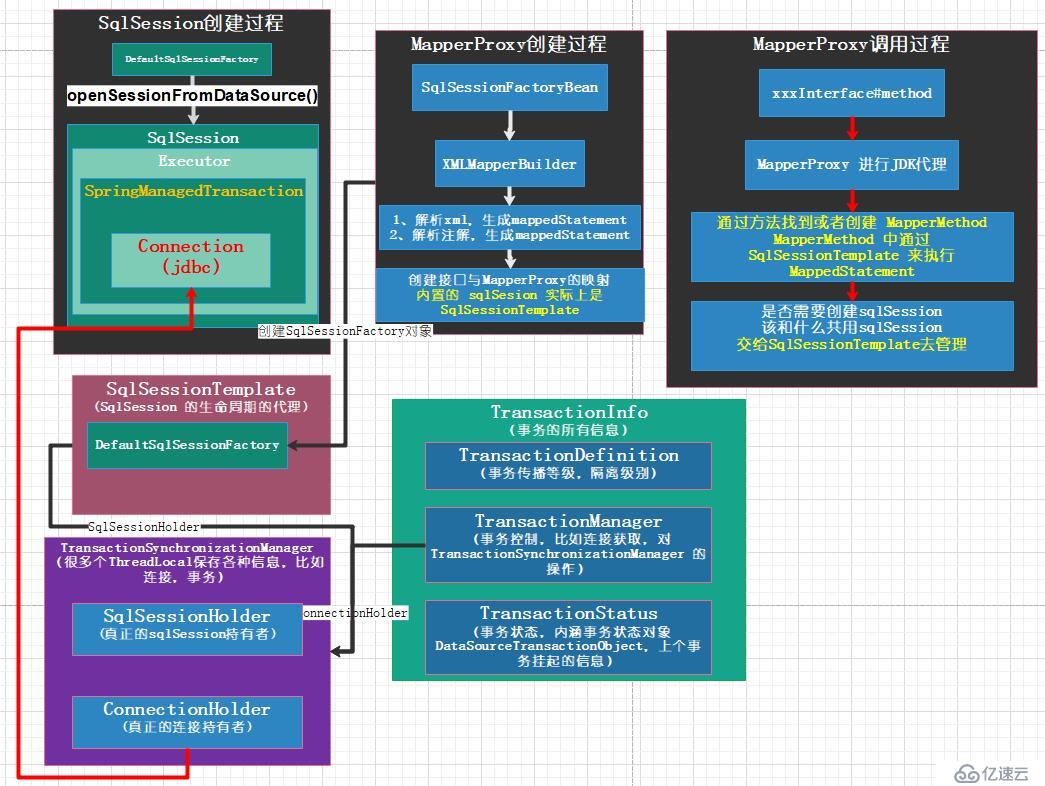
3.1 SqlSessionFactoryBean配置原理
SqlSessionFactoryBean像一座精心设计的工厂,负责生产MyBatis的核心会话对象。它实现了Spring的FactoryBean接口,这种设计模式让Bean的创建过程完全可控。当Spring容器初始化时,这个工厂Bean会读取各种配置参数,最终构建出功能完备的SqlSessionFactory。
配置数据源是第一步,没有数据源的SqlSessionFactory就像没有引擎的汽车。configLocation属性允许你引入独立的MyBatis配置文件,那里可以定义类型别名、插件链等全局设置。mapperLocations属性则指向那些XML映射文件,它们包含了具体的SQL语句和结果映射。
有次我在配置typeAliasesPackage时遇到问题,包路径写错导致类型解析失败。正确的包名配置能让MyBatis自动扫描实体类并注册简写名称,在映射文件中就不需要写完整的类路径了。
plugins属性支持拦截器链配置,分页插件、性能监控工具都可以在这里注入。这种扩展机制让MyBatis保持核心简洁的同时,又能满足各种定制化需求。
3.2 MapperScannerConfigurer工作机制
MapperScannerConfigurer是个聪明的扫描器,它在Spring容器启动后执行,自动发现Mapper接口并完成注册。basePackage属性定义了扫描范围,支持通配符和多个包路径。
它的工作原理基于Spring的BeanDefinitionRegistryPostProcessor。这个后置处理器在Bean定义加载完成后执行,能够动态添加新的Bean定义。每个符合条件的Mapper接口都会被包装成MapperFactoryBean,这是一个代理工厂,负责创建实际的Mapper实例。
annotationClass属性可以过滤只扫描特定注解标记的接口。在某些大型项目中,这种精细控制很有必要,避免扫描到不应该被管理的接口。
nameGenerator属性允许自定义Bean命名策略。默认情况下Bean名称就是接口名,但有时需要遵循特定的命名规范。我曾经在迁移老项目时遇到过命名冲突,通过自定义名称生成器顺利解决了问题。
sqlSessionFactoryRef属性在多个数据源场景下特别重要。它明确指定使用哪个SqlSessionFactory,确保Mapper接口连接到正确的数据库。
3.3 事务管理器集成方案
事务管理器是数据一致性的守护者,在MyBatis-Spring整合中通常选择DataSourceTransactionManager。它直接基于数据源管理事务,通过ThreadLocal保存当前线程的事务状态。
@Transactional注解的织入过程很精妙。Spring通过AOP在方法调用前后插入事务逻辑,开启事务、提交或回滚都在这个切面中完成。这种声明式事务管理让业务代码保持干净,不需要掺杂事务控制代码。
事务传播行为值得深入理解。REQUIRES_NEW总会启动新事务,挂起当前事务直到新事务完成。NESTED在支持保存点的数据库中创建嵌套事务,这种细粒度控制在某些复杂业务中很实用。
隔离级别的选择影响并发性能。REPEATABLE_READ能防止不可重复读,但可能增加锁竞争。根据业务的数据一致性要求和并发压力,选择适当的隔离级别是个技术活。
超时设置经常被忽视。timeout属性定义事务必须在指定秒数内完成,否则自动回滚。这个配置在防止长时间锁等待方面很有价值。
3.4 多数据源配置策略
多数据源配置像管理多个数据库连接池,每个数据源都有独立的生命周期和配置参数。主从分离、分库分表等场景都需要这种能力。
定义多个SqlSessionFactory是关键步骤。每个Factory绑定特定的数据源和Mapper包路径,确保数据访问操作路由到正确的数据库。@Primary注解标记主数据源,避免自动装配时的歧义。
事务管理器也需要对应多个实例。每个SqlSessionFactory配套一个TransactionManager,使用@Qualifier在注入时明确指定。这种明确性虽然增加了配置复杂度,但避免了潜在的路由错误。
动态数据源切换是更高级的方案。通过AbstractRoutingDataSource和线程上下文,可以在运行时根据业务逻辑切换数据源。读写分离场景下,查询操作指向从库,写操作指向主库,这种设计能有效分摊数据库压力。
配置顺序有时会影响初始化过程。我建议先配置数据源,再配置SqlSessionFactory,最后配置事务管理器。这种层次化的配置方式逻辑清晰,也便于后续维护和问题排查。
4.1 用户管理系统案例实现
用户管理系统是检验MyBatis-Spring整合效果的典型场景。我们从实体类设计开始,User类包含id、username、email、createTime等字段。这些字段与数据库表列名对应,MyBatis的自动映射机制能大大减少配置工作量。
Mapper接口定义数据操作契约。UserMapper包含insert、deleteById、update、selectById等基本方法,方法名与XML映射文件中的SQL语句id精确匹配。这种接口与实现的分离让代码结构更清晰,也便于单元测试。
XML映射文件编写需要特别注意。parameterType指定传入参数类型,resultType定义返回结果映射。对于复杂对象关系,可以使用resultMap进行精细映射配置。记得有次我忘记在resultMap中配置id字段,导致关联查询结果异常,这个细节值得关注。
Service层封装业务逻辑。UserService注入UserMapper,在基本CRUD操作基础上添加业务校验。比如用户注册时需要检查用户名是否重复,这个逻辑放在Service层比在Mapper层更合适。
Controller层处理HTTP请求。使用@RestController注解标记,每个方法对应特定的API端点。参数校验、异常处理、响应封装都在这一层完成。Spring的依赖注入让各层组件自然衔接,整个架构浑然一体。
4.2 商品信息管理模块开发
商品管理涉及更多复杂关系。Product实体与Category、ProductImage等实体关联,这种一对多、多对一关系在MyBatis中通过关联映射处理。
动态SQL在商品查询中发挥重要作用。<where>标签自动处理条件拼接,避免WHERE关键字多余或缺失。<if>标签根据参数动态生成查询条件,比如按价格区间、分类、关键词搜索等场景。
我曾在商品列表查询中遇到N+1查询问题。每次获取商品信息都要额外查询分类信息,性能急剧下降。通过<association>配置一次性加载关联数据,或者使用join查询在单次数据库访问中获取完整信息,都能有效解决这个问题。
批量操作在商品导入场景很常见。SqlSession的batch模式能显著提升插入效率,特别是在初始化数据时。foreach标签配合批量插入语句,比单条插入性能提升数倍。
乐观锁防止并发更新冲突。在Product表中添加version字段,每次更新时检查版本号。这种轻量级并发控制机制,比悲观锁更适合高并发电商场景。
4.3 复杂查询与分页处理
分页查询几乎是每个系统的标配。PageHelper插件让分页变得简单,只需要在查询方法前调用PageHelper.startPage,后续的查询就会自动分页。这个插件通过拦截器修改执行的SQL,添加limit语句实现分页。
多表关联查询考验映射配置能力。resultMap支持嵌套association和collection,能够构建复杂的对象图。但要注意避免循环引用,Jackson在序列化时会陷入死循环。@JsonIgnore注解可以打破这种循环。
统计查询需要处理聚合结果。MyBatis支持将查询结果映射到非实体类,比如包含count、sum等统计字段的DTO对象。这种灵活性让数据展示层能够获得任何需要的数据结构。
动态排序让用户体验更友好。order by字段和排序方向都可以通过参数动态指定。但要注意SQL注入风险,不要直接将用户输入拼接到order by子句中。安全的做法是提供有限的排序选项,或者在后台进行严格校验。
查询缓存需要谨慎使用。一级缓存默认开启,在同一个SqlSession内有效。二级缓存可以跨Session,但要注意数据一致性问题。在读写频繁的场景下,缓存的更新策略需要精心设计。
4.4 事务处理最佳实践
声明式事务让代码保持简洁。@Transactional注解放在Service方法上,定义事务边界。默认情况下,Spring只在抛出RuntimeException时回滚事务,通过rollbackFor属性可以扩展回滚的异常类型。
事务方法调用需要理解代理机制。在同一个类中方法互相调用时,被调用方法的事务注解不会生效,因为这是直接方法调用而非代理调用。将事务方法拆分到不同Service中,或者使用AspectJ模式可以解决这个问题。
读写分离场景下的事务路由值得注意。标记为@Transactional的方法默认使用写数据源,确保数据一致性。只读查询可以使用@Transactional(readOnly = true),这样可能会被路由到读库,提升查询性能。
事务超时设置保护系统资源。长时间运行的事务可能持有数据库锁,影响其他操作。根据业务特点设置合理的超时时间,比如批量处理可以设置较长的超时,而用户交互操作应该快速完成。
测试事务行为需要特殊配置。在单元测试中,默认每个测试方法都在事务中执行,测试完成后自动回滚。这种机制保证测试数据不会污染数据库,也避免了手动清理的麻烦。
5.1 连接池配置优化
数据库连接是系统性能的关键瓶颈。选择合适的连接池并合理配置参数,往往能让应用性能得到质的提升。
HikariCP以其轻量高效著称,成为Spring Boot默认连接池。配置时重点关注maximumPoolSize,这个值不是越大越好。根据数据库最大连接数和应用实例数量合理设置,避免耗尽数据库资源。我记得有个项目将连接池大小设为200,结果数据库频繁告警,调整到50后反而性能更稳定。
minIdle设置保持一定数量的空闲连接,避免突发请求时创建连接的开销。但设置过高会浪费资源,一般建议设为maximumPoolSize的1/4左右。connectionTimeout控制获取连接的最大等待时间,在网络不稳定的环境中适当调大这个值。
validationQuery用来检测连接有效性。"SELECT 1"是最简单的选择,但某些数据库可能有更优化的检测方式。连接泄漏检测通过leakDetectionThreshold设置,能在开发阶段及时发现未关闭的连接。
监控连接池状态很有必要。通过JMX或特定端点暴露连接池指标,观察活跃连接数、空闲连接数、等待线程数等数据。这些实时指标能帮助发现配置不合理的地方。
5.2 缓存机制应用策略
MyBatis提供两级缓存机制,合理使用能显著减少数据库访问。一级缓存基于SqlSession,在同一个会话中相同查询直接返回缓存结果。这个特性让连续的相同查询变得高效。
二级缓存需要显式开启,在mapper XML中配置<cache/>标签。二级缓存的生命周期与SqlSessionFactory相同,能够跨会话共享数据。但要注意缓存的对象必须是可序列化的,且要考虑数据一致性问题。
缓存策略选择很重要。LRU(最近最少使用)适合大多数场景,FIFO(先进先出)更简单但可能淘汰热点数据。缓存的flushInterval设置定时刷新,避免脏数据存留过久。
我遇到过缓存导致的数据不一致问题。在多个应用实例共享缓存时,一个实例更新数据后,其他实例的缓存不会自动失效。通过Redis等集中式缓存解决方案,或者设置较短的过期时间可以缓解这个问题。
查询结果缓存不是万能的。对于更新频繁的数据,缓存反而会增加系统复杂度。只对那些相对静态、查询频繁的数据使用缓存,比如配置信息、基础数据字典等。
5.3 常见异常处理方案
BindingException是新手常遇到的异常,通常因为Mapper接口方法与XML映射文件不匹配。检查方法名、参数类型、返回值类型是否一致,这种问题往往在启动阶段就能发现。
DataIntegrityViolationException涉及数据完整性约束。可能是插入了重复的主键,或者违反了外键约束。在业务代码中进行前置校验,比依赖数据库抛出异常更友好。
PersistenceException包装了各种持久化异常。通过getCause()方法获取根本原因,针对性地处理。比如连接超时、SQL语法错误、锁超时等,每种情况都需要不同的处理策略。
事务回滚异常需要特别注意。默认只回滚RuntimeException,checked异常不会触发回滚。通过@Transactional(rollbackFor=Exception.class)可以扩展回滚范围,但要谨慎使用,避免不必要的回滚。
我习惯在全局异常处理器中统一处理持久层异常。将技术异常转换为业务异常,给用户更友好的提示。记录详细的错误日志和上下文信息,便于后续排查问题。
5.4 生产环境部署建议
日志配置要兼顾可读性和性能。开发环境可以使用DEBUG级别,生产环境建议调到INFO或WARN。SQL日志单独配置,通过mybatis.configuration.log-impl指定日志实现,避免输出过多调试信息。
监控指标收集很重要。除了连接池指标,还要关注SQL执行时间、慢查询统计、缓存命中率等。这些数据能帮助发现性能瓶颈,指导后续优化方向。
数据库连接验证在容器化部署中很关键。配置testOnBorrow或testOnReturn确保连接的可用性,特别是在服务启动时,要等待数据库就绪后再接受请求。
资源清理要彻底。应用关闭时确保数据库连接正确释放,线程池优雅关闭。这些细节在开发环境可能不明显,但在生产环境频繁部署时会暴露问题。
配置分离让部署更灵活。数据库连接信息、缓存配置等环境相关参数放在配置中心或外部文件。不同环境使用不同配置,避免将生产环境配置误用到测试环境。