还记得第一次在Java优学网项目中遇到多表查询时的情景。那是个用户管理模块的需求,需要同时获取用户基本信息和他们的学习记录。面对这个看似简单的需求,我却陷入了深深的困惑。
第一次在Java优学网遇到多表查询的挑战
当时我已经熟练掌握了单表CRUD操作,自信满满地准备大展身手。但当看到需求文档上写着“需要同时展示用户信息和对应的课程学习进度”时,我突然意识到事情没那么简单。
数据库里用户表和课程表是分开的,用户学习记录又存储在另一个表中。这三个表之间存在着复杂的关联关系。我尝试着写了好几个单独的查询,然后在代码里手动组装数据。结果代码变得又长又乱,性能也差强人意。
那段时间我经常加班到深夜,就为了搞清楚如何优雅地处理这些表关联。有时候明明在MySQL Workbench里测试通过的SQL语句,放到MyBatis里就各种报错。我记得有个周五晚上,为了一个关联查询问题调试到凌晨两点,最后发现是resultMap配置写错了属性名。
面对复杂业务逻辑时的迷茫与挣扎
随着Java优学网项目的深入,业务逻辑变得越来越复杂。某个页面需要展示用户信息、学习课程、作业提交情况、教师评价等多个维度的数据。这些数据分布在五六个不同的表中,关联关系错综复杂。
最让人头疼的是,不同的业务场景需要不同的关联深度。有些页面只需要基本信息,有些则需要完整的关联数据。我开始怀疑自己的技术选择,甚至考虑要不要放弃MyBatis改用其他方案。
那段时间我经常在技术论坛上搜索相关问题的解决方案,看到别人分享的优雅代码,既羡慕又焦虑。有次我在Stack Overflow上看到一个类似的问题,下面的回答提到了MyBatis的association和collection标签,这让我眼前一亮。
从简单单表查询到关联查询的转变契机
转机出现在一次代码评审中。团队里的一位资深工程师看了我那些冗长的查询代码,轻轻说了句:“为什么不试试MyBatis的关联查询呢?”这句话点醒了我。
我开始系统地学习MyBatis的关联查询功能。从最简单的
有意思的是,当我真正掌握了关联查询后,发现之前的很多复杂代码都可以简化。原来需要几十行代码才能完成的数据组装,现在几行配置就能搞定。这种从量变到质变的学习体验,让我深刻理解了“工欲善其事,必先利其器”的道理。
现在回想起来,那段困惑期其实是每个开发者成长的必经之路。从单表查询到关联查询的转变,不仅仅是技术层面的提升,更是思维方式的变化。我们需要学会用更抽象的视角看待数据之间的关系,这正是MyBatis关联查询想要教会我们的。
掌握了基础概念后,我开始在Java优学网项目中真正应用关联查询。这个过程就像学游泳,光在岸上看理论是不够的,必须跳进水里才能真正理解。
一对一关联查询的实战演练
用户和用户详情表的关系是最典型的一对一关联。在Java优学网中,每个注册用户都对应一个扩展信息表,存储着头像路径、个人简介等补充数据。
我最初的做法很笨拙——先查询用户表,再根据用户ID去查详情表。后来发现MyBatis的<association>标签能优雅解决这个问题。配置起来其实很简单,在resultMap里嵌套一个association,指定对应的Java类型和列映射关系就行。
记得有次配置时犯了个低级错误,把property写成了propety,调试了半天才发现问题。这种细节上的疏忽在初学阶段很常见,但正是这些错误让我对配置的理解更加深刻。
一对多关联查询的巧妙运用
课程与章节的关系就是典型的一对多。在Java优学网里,一门编程课程包含多个教学章节,这就需要用到<collection>标签。
刚开始我总搞混association和collection的使用场景。后来总结了个简单区分方法:association对应“有一个”,collection对应“有多个”。比如用户有一个详情,课程有多个章节。
实际开发中,我发现collection的配置比association要复杂一些。需要特别注意ofType属性的设置,它指定了集合中元素的类型。有次我忘记配置这个属性,结果查询出来的数据全是null,排查了好久才找到原因。
多对多关联查询的解决方案
用户和课程之间的收藏关系是最经典的多对多关联。在数据库层面,这需要通过中间表来实现。
MyBatis处理多对多关联时,本质上还是组合使用association和collection。比如要查询用户收藏的所有课程,就需要先通过用户-课程中间表找到关联的课程ID,再关联到课程表获取详细信息。
这种多层嵌套的配置刚开始让我很头疼。后来我学会先理清业务关系,再设计对应的resultMap结构。先画出示意图,明确各表之间的关联关系,编码时就能事半功倍。
嵌套查询与嵌套结果的区别与选择
这是关联查询中最容易混淆的两个概念。嵌套查询(分次查询)是执行多条SQL语句,在内存中组装结果;嵌套结果(连接查询)是通过JOIN语句一次查询出所有数据。
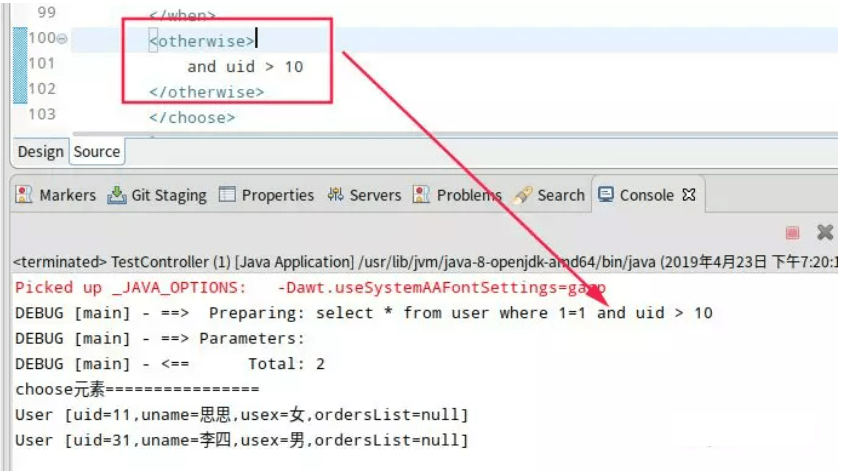
在Java优学网的用户主页开发中,我两种方式都尝试过。嵌套查询的配置更清晰,适合关联数据较多但不一定全部需要的场景;嵌套结果的性能更好,适合关联数据都需要立即使用的场景。
有个经验值得分享:当关联层级超过三层时,建议使用嵌套查询,否则SQL语句会变得过于复杂难以维护。我在开发课程详情页时就遇到过这个问题,一个七表关联的查询语句写了将近二十行,后来拆分成多个嵌套查询后清晰多了。
关联查询的核心在于理解数据之间的关系。当我真正掌握这些机制后,发现之前很多复杂的业务需求都能用很简洁的方式实现。这种从混乱到清晰的过程,大概是每个开发者最享受的技术成长体验。
当我在Java优学网项目中熟练使用各种关联查询后,新的挑战出现了。随着用户量和数据量的增长,一些原本运行良好的查询开始变得缓慢。这让我意识到,掌握关联查询的使用只是第一步,优化性能才是真正的考验。
懒加载与急加载的权衡抉择
第一次注意到性能问题是在用户个人中心页面。这个页面需要展示用户基本信息、学习记录、收藏课程等多项数据。最初我配置的是急加载,所有关联数据都会一次性查询出来。
直到某天监控系统报警,发现这个页面的数据库查询耗时突然增加了三倍。检查后发现,有些用户收藏了上百门课程,每次打开个人中心都会加载全部课程信息,而实际上用户可能只需要查看其中几门。
改成懒加载后效果立竿见影。MyBatis的fetchType="lazy"配置让关联数据只在真正访问时才进行查询。我记得有个用户反馈说页面加载变快了,这种优化带来的用户体验提升让人很有成就感。
不过懒加载也不是万能药。在课程详情页这种需要立即展示所有关联数据的场景,使用懒加载反而会导致更多的数据库请求。关键是要根据业务场景灵活选择。
N+1查询问题的发现与解决
N+1问题是我在优化过程中遇到的最隐蔽的性能杀手。有次排查一个列表页面的性能问题,发现虽然只查询了10条记录,却产生了11次数据库请求。
问题出在课程列表的讲师信息展示上。我配置的是嵌套查询,先查询课程列表,再为每条课程单独查询讲师信息。10门课程就产生了10次额外的查询。
改用嵌套结果后,通过JOIN语句一次性获取所有数据,查询次数从11次降到了1次。这个改进让页面响应时间从原来的2秒多降到了300毫秒以内。
现在我在写关联查询时都会先问自己:这里会不会产生N+1问题?这种警惕性就是在一次次踩坑中培养出来的。
缓存机制在关联查询中的应用
缓存是提升关联查询性能的另一把利器。Java优学网的课程分类数据变化频率很低,但几乎每个页面都需要用到。最初每次查询都要访问数据库,给数据库造成了不小压力。
引入MyBatis二级缓存后,分类数据只在第一次查询时访问数据库,后续请求都直接从缓存读取。我还记得配置缓存后,数据库监控图上的QPS明显下降的那个瞬间。
但缓存的使用需要很谨慎。用户个性化的数据,比如学习进度、收藏状态就不适合缓存。有次我错误地缓存了用户特定的数据,导致不同用户看到了相同的学习记录,幸好测试阶段就发现了这个问题。

索引优化对查询性能的提升
数据库层面的优化往往能带来最直接的性能提升。在Java优学网的用户-课程收藏关系中,最初查询用户收藏课程需要3-4秒。
通过EXPLAIN分析SQL执行计划,发现是在关联字段上缺少索引。在user_id和course_id上创建复合索引后,同样的查询只需要几十毫秒。
索引优化有个经验之谈:关联查询的JOIN条件字段一定要建立索引。我在团队内部分享时经常强调这一点,因为很多性能问题其实都是索引缺失导致的。
性能优化是个持续的过程。每个优化方案都需要结合实际业务场景来评估,没有放之四海而皆准的规则。重要的是建立性能意识,在编码时就能预见可能的性能瓶颈。
在性能优化的探索之后,我开始将这些理论应用到Java优学网的具体业务场景中。真实的项目开发让我明白,关联查询不仅仅是技术实现,更是业务逻辑的直观体现。每个关联关系背后都对应着特定的用户需求和业务规则。
用户与文章的关联查询实现
用户和文章的一对多关系是Java优学网最基础的关联场景。每个用户可以发布多篇文章,而每篇文章都归属于特定用户。
最初的设计很简单:在文章表中添加user_id字段。但在实际查询时遇到了问题——当需要同时展示文章内容和作者信息时,不得不进行两次查询。后来改用MyBatis的<association>标签,通过JOIN查询一次性获取所有数据。
我印象很深的是处理用户头像展示的需求。文章列表需要显示作者头像,而头像存储在用户表的avatar字段。使用关联查询后,原本需要循环查询用户信息的代码变得简洁很多。这种改进不仅提升了性能,也让代码更易于维护。
课程与分类的多级关联处理
课程分类系统是Java优学网的另一个核心功能。课程属于二级分类,二级分类又属于一级分类,形成了多级关联关系。
处理这种层级关联时,我采用了嵌套的<collection>标签。先查询一级分类,然后通过关联查询获取对应的二级分类,最后获取每个二级分类下的课程列表。
记得有次产品经理想要在首页展示“编程语言→Java→Spring框架”这样的完整分类路径。多级关联查询正好解决了这个问题,通过一次查询就能构建出完整的面包屑导航。这种设计让分类体系更加清晰,用户也能更好地理解课程的组织结构。
评论系统的嵌套关联设计
评论系统可能是最复杂的关联场景。一篇文章可以有多个评论,每个评论可以有多个回复,回复还可以继续被回复,形成树形结构。
我采用自关联的方式处理这种嵌套关系。在评论表中添加parent_id字段指向父级评论,然后使用递归关联查询构建完整的评论树。
实现过程中有个有趣的发现:当评论层级过深时,递归查询会影响性能。后来我们设置了最大嵌套层级限制,既保证了功能完整性,又避免了性能问题。这种平衡在实际开发中经常需要考量。
复杂业务场景下的关联查询最佳实践
在Java优学网的运营过程中,逐渐积累了一些关联查询的最佳实践。比如首页的推荐课程模块,需要关联课程信息、讲师详情、学习人数统计等多个数据源。
这种情况下,我倾向于使用多个简单的关联查询替代一个复杂的多表JOIN。虽然可能增加查询次数,但代码的可读性和可维护性更好。特别是在需要动态调整查询条件时,这种设计的优势更加明显。
另一个经验是关于关联查询的粒度控制。不是所有场景都需要完整的关联数据,有时候只需要关联对象的某个字段。比如在课程列表页,可能只需要讲师的姓名,而不需要完整的讲师信息。这时候使用<association>的select属性只查询必要字段,能有效减少数据传输量。
关联查询的实战经验告诉我,技术方案的选择永远要服务于业务需求。最优雅的解决方案不一定是最合适的,能够在性能、可维护性和开发效率之间找到平衡点的方案才是最好的。
经过在Java优学网项目中的实战应用,我发现关联查询的掌握程度直接影响着开发效率和系统性能。那些看似简单的配置背后,往往隐藏着值得深思的设计哲学。就像搭积木,基础组件相同,但搭建方式决定了最终成果的稳固与美观。
动态SQL在关联查询中的灵活运用
动态SQL让关联查询从静态配置变成了智能化的数据获取工具。在Java优学网的搜索功能中,用户可能根据课程名称、讲师、分类等多个条件进行筛选,每个条件的组合都会影响关联查询的表连接方式。
我习惯使用<if>标签配合<choose>标签构建动态关联查询。当用户选择特定分类时,自动添加分类表的JOIN条件;当需要筛选讲师时,才引入讲师表的关联。这种按需关联的方式避免了不必要的表连接,显著提升了查询效率。
记得有次处理课程筛选功能,产品要求根据用户的学习进度动态显示不同的关联数据。已购买的课程需要显示学习进度,未购买的课程只需要基础信息。通过动态SQL控制关联字段的查询,完美实现了这个需求。这种灵活性让代码能够适应不断变化的业务需求。
分页查询与关联查询的结合
分页和关联查询的结合是个技术难点。直接在关联查询的结果上分页会导致数据错乱,因为JOIN操作可能使主表记录重复出现。
我的解决方案是分两步处理:先对主表进行分页查询获取ID列表,再根据ID列表执行关联查询。虽然增加了查询次数,但保证了分页的准确性。在Java优学网的课程列表页,这种方案经受住了大量数据的考验。
另一个技巧是使用子查询优化分页性能。先通过子查询获取分页范围的主键,再进行关联查询,避免了大数据量的JOIN操作。这种方法在课程评论列表这类深度分页场景中效果特别明显。
关联查询的调试与问题排查
关联查询的调试比单表查询复杂得多。我总结了一套自己的调试方法:先从最简单的查询开始,逐步添加关联条件,每步都验证结果的正确性。
使用MyBatis的日志输出功能是个好习惯。通过查看实际执行的SQL语句,能够快速定位问题所在。在Java优学网开发过程中,我养成了在测试环境开启DEBUG日志的习惯,这帮助我发现了多个关联查询的潜在问题。
性能问题的排查更需要系统化的方法。有一次课程列表页加载缓慢,通过分析执行计划发现是缺失索引导致的全表扫描。添加合适的索引后,查询时间从2秒降低到200毫秒。这个经历让我明白,关联查询的性能优化需要从数据库层面着手。
从Java优学网项目中学到的宝贵经验
在Java优学网项目的开发过程中,我积累了一些关联查询的实用经验。这些经验可能不够系统,但都很实用。
关联不是越多越好。早期我倾向于一次性查询所有关联数据,后来发现这会导致查询复杂度和内存占用急剧上升。现在我会仔细评估每个关联的必要性,只查询当前业务场景需要的数据。
缓存策略需要根据关联数据的更新频率来设计。用户基本信息这类变化不大的数据适合缓存,而课程学习进度这种频繁更新的数据则不适合。在Java优学网中,我们为不同类型的关联数据设计了不同的缓存策略。
代码的可读性同样重要。过于复杂的关联查询虽然可能提升性能,但会给后续维护带来困难。我现在的做法是在性能和可维护性之间寻找平衡点,必要时添加详细的注释说明关联关系。
关联查询教会我的不仅是技术实现,更是数据建模的思维方式。每个关联都代表着业务实体之间的关系,理解这些关系背后的业务逻辑,才能设计出合理的查询方案。技术为业务服务,这个原则在关联查询中体现得尤为明显。