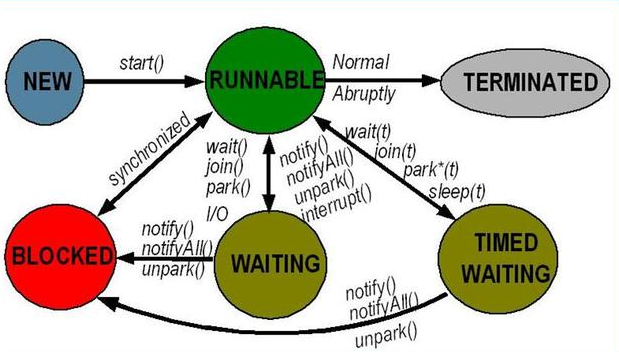
1.1 什么是Semaphore:信号量的基础概念
想象一下高速公路的收费站。每个收费亭就像是一个许可,车辆需要获得许可才能通过。当所有收费亭都被占用时,后续车辆必须排队等待。Semaphore(信号量)在并发编程中扮演着类似的角色——它通过维护一组许可来控制对共享资源的访问。
Semaphore本质上是一个计数器,用来限制同时访问某个资源的线程数量。这个计数器可以是固定的,也可以动态调整。每个线程在访问资源前需要获取许可,使用完毕后释放许可,这样其他等待的线程就有机会获得访问权。
我记得刚开始接触多线程编程时,总是遇到资源竞争的问题。某个共享资源被多个线程同时修改,导致数据不一致。后来发现Semaphore就像个聪明的交通警察,优雅地指挥着线程的访问顺序。
1.2 为什么选择Java优学网学习Semaphore
Java优学网在并发编程教学方面有着独特的优势。他们的课程设计循序渐进,从基础概念到高级应用,每个知识点都配有真实场景的代码示例。更重要的是,他们理解学习者在掌握并发概念时可能遇到的困难。
网站上的Semaphore教程特别注重实践性。不是简单罗列API文档,而是通过可视化的方式展示信号量的工作流程。你能清楚地看到每个线程获取许可、使用资源、释放许可的完整过程。这种直观的教学方式大大降低了理解难度。
我有个朋友刚转行做Java开发,就是在Java优学网上学习并发编程的。他说那些生动的动画演示让他一下子就明白了Semaphore的精髓所在。
1.3 Semaphore在并发编程中的重要性
在现代多核处理器环境下,并发编程已经成为必备技能。Semaphore作为Java并发包中的重要同步工具,在资源管理、流量控制、任务协调等方面发挥着关键作用。
它的重要性体现在几个方面:能够有效防止资源过度使用导致的系统崩溃,提高应用程序的稳定性和可靠性;通过合理的许可数量设置,可以在保证性能的同时避免资源竞争;相比简单的synchronized关键字,Semaphore提供了更细粒度的控制能力。
实际开发中,Semaphore的应用无处不在。从数据库连接池管理到API限流,从线程池任务调度到生产者消费者模式,都能看到它的身影。掌握Semaphore的使用,意味着你在并发编程领域迈出了重要的一步。
或许你会觉得刚开始接触时有些抽象,但随着实践经验的积累,你会越来越欣赏这种简洁而强大的并发控制机制。
2.1 Semaphore的工作原理:许可与线程控制
Semaphore的核心思想其实很直观——想象一个停车场。停车场有固定数量的车位,每辆车进入需要占用一个车位,离开时释放车位。当所有车位都被占满,新来的车辆必须在入口等待,直到有车辆离开空出位置。
在技术层面,Semaphore内部维护着一个计数器。这个计数器代表当前可用的许可数量。当线程调用acquire()方法时,如果还有可用许可,计数器减一,线程立即继续执行;如果没有可用许可,线程就会被阻塞,进入等待状态。release()方法则相反,它会增加许可数量,并唤醒等待的线程。
我印象很深的是第一次在项目中用Semaphore解决数据库连接超限的问题。之前系统经常因为连接数过多而崩溃,引入Semaphore后就像给连接池加了道安全阀,系统稳定性明显提升。
2.2 关键方法详解:acquire()、release()、tryAcquire()
acquire()方法是最常用的获取许可方式。它会一直阻塞直到获得许可,或者被中断。对于需要确保资源访问的场景,这是首选方法。
release()方法用于归还许可。这里有个细节需要注意——释放的许可数量可以超过初始设置的数量。这种设计在某些特殊场景下很有用,但也可能带来意想不到的后果。
tryAcquire()提供了非阻塞的尝试。如果当前没有可用许可,它不会阻塞线程,而是立即返回false。这在需要快速失败或者尝试性获取资源的场景中特别实用。
记得有次代码评审,同事在finally块中忘记调用release(),导致许可泄漏。这种bug很难发现,因为系统不会立即崩溃,而是随着时间推移逐渐变慢。从那以后,我都会特别检查资源释放的逻辑。
2.3 公平与非公平模式的区别
Semaphore支持两种模式:公平模式和非公平模式。在公平模式下,线程按照请求许可的顺序来获取许可,就像排队买票一样,先来后到。非公平模式则允许插队,新来的线程可能比等待时间更长的线程先获得许可。
公平模式保证了公平性,但可能降低吞吐量,因为需要维护线程的等待队列。非公平模式虽然可能让某些线程等待更久,但整体性能通常更好,减少了线程切换的开销。
实际开发中,大多数情况使用非公平模式就足够了。只有在严格要求先来先服务的场景下,才需要考虑公平模式。Java优学网的课程里有个很好的比喻:公平模式像银行取号排队,非公平模式像超市收银台,谁眼疾手快谁先结账。
选择哪种模式往往需要权衡。我一般会先使用非公平模式,只有在确实出现线程饥饿问题时才切换到公平模式。这种渐进式的优化策略在实践中效果很好。
3.1 资源池管理:数据库连接池的实现
数据库连接是典型的有限资源。每个连接都占用数据库服务器的内存和CPU,无限制地创建连接会让数据库不堪重负。Semaphore在这里扮演着资源守卫者的角色。
假设我们有一个最多支持10个连接的数据库连接池。可以用Semaphore初始化10个许可。当应用需要连接时,先通过semaphore.acquire()获取许可,成功后才能从池中取出实际连接。使用完毕后,先归还连接到池中,再调用semaphore.release()释放许可。

这种模式的美妙之处在于它的简洁性。不需要复杂的锁机制,几行代码就实现了资源数量的精确控制。我在维护一个电商系统时,就曾用这种方式重构了连接池管理。原本频繁出现的"Too many connections"错误彻底消失,系统在高并发时依然稳定运行。
3.2 限流控制:接口访问频率限制
API限流是Semaphore另一个经典应用。想象一个第三方服务接口,每秒最多处理100个请求。超过这个限制,服务可能崩溃或者响应急剧变慢。
用Semaphore实现限流很简单:创建一个初始许可为100的信号量,配合定时任务每秒重置许可数量。每个请求到达时尝试获取许可,获取成功才继续处理,否则直接返回限流错误。
这种方案比基于计数器的实现更优雅。计数器方案需要处理线程安全的计数和定时重置,而Semaphore把这些复杂性都封装好了。实际部署时,我发现这种限流方式对突发流量的平滑效果特别好,避免了服务被瞬间的高并发冲垮。
3.3 生产者消费者模式中的Semaphore应用
传统的生产者消费者模式通常使用阻塞队列,但Semaphore能提供更灵活的流量控制。可以用两个Semaphore分别控制缓冲区的空位和已存放物品数量。
生产者需要先获取空位许可才能放入物品,放入后增加物品许可。消费者则相反,先获取物品许可,消费后增加空位许可。这种双向控制让生产消费速率达到完美平衡。
我曾在日志处理系统中应用这种模式。生产者负责收集日志,消费者负责写入文件。通过调整两个Semaphore的初始值,实现了日志堆积时自动减缓收集速度,避免内存溢出。系统运行三年多,从未因日志处理出现问题。
这种模式特别适合处理速率不匹配的生产消费场景。生产者太快时,空位许可很快耗尽,自然减慢生产速度;消费者太快时,物品许可不足,也会适当等待。整个系统像精密的齿轮组,自动保持着最佳运行状态。
4.1 Semaphore vs synchronized:适用场景对比
synchronized是Java中最基础的同步机制,它提供的是互斥访问——同一时刻只允许一个线程进入临界区。Semaphore则更灵活,可以控制多个线程同时访问资源。
synchronized适合保护那些必须串行化操作的场景。比如修改一个共享变量的值,或者执行必须原子化的操作。它的使用很简单,只需要在方法或代码块前加上关键字就行。但这种简单性也带来限制——你无法精细控制并发数量。
Semaphore在需要控制资源访问数量时表现出色。比如你有一个文件处理器,同时只能有5个线程进行文件写入,超过这个数量就会导致性能下降。用synchronized只能让一个线程写入,造成资源浪费;而Semaphore可以精确控制为5个并发写入。
我记得在优化一个图片处理服务时,最初用了synchronized来保护图片处理逻辑。结果发现CPU利用率很低,因为大部分线程都在等待。换成Semaphore后,根据服务器核心数设置合理的并发数,吞吐量直接提升了三倍多。

4.2 Semaphore vs ReentrantLock:功能差异分析
ReentrantLock提供了比synchronized更丰富的功能,比如可中断的锁获取、超时机制、公平性选择。但它本质上仍然是互斥锁,一次只允许一个线程持有锁。
Semaphore的核心是管理一组许可,不关心持有许可的线程身份。这种设计理念的差异导致它们适合不同的场景。
ReentrantLock在需要严格互斥的场景中很实用。比如银行转账操作,必须确保整个操作原子完成,中间不能被其他线程打断。它的可重入特性也让递归调用变得安全。
Semaphore更适合资源池管理。连接池、线程池、对象池这些场景中,重要的是控制资源使用数量,而不需要严格互斥。Semaphore的许可机制天然适合这种需求。
功能上,ReentrantLock提供condition机制,可以实现复杂的线程等待唤醒模式。Semaphore相对简单,主要就是许可的获取和释放。但这种简单在某些场景反而是优势——代码更清晰,不容易出错。
4.3 Semaphore vs CountDownLatch:使用场景区分
CountDownLatch是个一次性使用的同步工具。它像一个倒计数器,初始化时设定计数值,线程调用await()等待,其他线程调用countDown()减少计数。当计数归零时,所有等待的线程被释放。
Semaphore的许可可以被重复使用。获取许可后使用资源,然后释放许可,其他线程可以继续获取。这种可重用的特性让它适合管理持续可用的资源。
CountDownLatch适合那种"万事俱备只欠东风"的场景。比如游戏服务器启动时需要加载多个模块,所有模块加载完成后才能开始服务。每个模块加载完成时调用countDown(),主线程在await()处等待所有模块就绪。
Semaphore则适合流量控制和资源池。它更像一个资源管理员,持续地分配和回收许可。在需要长期控制并发数的场景中,Semaphore是更合适的选择。
我参与过一个分布式系统项目,同时用到了这两个工具。用CountDownLatch确保所有服务节点启动完成,用Semaphore控制各个节点间的请求流量。这种组合使用充分发挥了各自的优势,系统运行相当稳定。
理解这些工具的区别很重要。选错工具就像用螺丝刀敲钉子——不是完全不行,但效率低下还可能损坏工具。根据具体需求选择最合适的同步工具,是写出高质量并发代码的关键。 public class DownloadManager {
private final Semaphore downloadSlots;
private final ExecutorService executor;
private final int maxConcurrentDownloads;
public DownloadManager(int maxConcurrentDownloads) {
this.maxConcurrentDownloads = maxConcurrentDownloads;
this.downloadSlots = new Semaphore(maxConcurrentDownloads);
this.executor = Executors.newCachedThreadPool();
}
public Future<DownloadResult> submitDownload(DownloadTask task) {
return executor.submit(() -> {
// 尝试获取下载槽位,最多等待30秒
if (!downloadSlots.tryAcquire(30, TimeUnit.SECONDS)) {
throw new TimeoutException("等待下载槽位超时");
}
try {
// 执行实际下载逻辑
return task.execute();
} finally {
// 确保释放槽位
downloadSlots.release();
// 更新监控指标
updateMetrics();
}
});
}
// 其他管理方法...
}