数据库访问就像去图书馆找书。传统方式每次都要走到书架前翻阅,Redis则像把常用书籍放在手边的移动书架上。这个简单比喻背后,是两种截然不同的数据访问哲学。
传统数据库访问模式 vs Redis缓存模式
传统数据库访问像每次都要重新泡茶。用户请求到来,应用连接数据库,执行查询,获取结果,关闭连接。这个完整流程消耗着CPU、内存、网络资源。在高并发场景下,数据库很快会成为系统瓶颈。
Redis缓存模式改变了这种工作方式。它像在应用和数据库之间加了高速缓冲区。首次查询从数据库获取数据后,结果会被存储在Redis中。后续相同查询直接访问Redis获取数据,避免了数据库的重复访问。
我记得去年参与的一个电商项目,商品详情页的数据库查询占了总请求的70%。引入Redis后,相同硬件配置下系统吞吐量提升了近5倍。这种改变不仅仅是性能提升,更是架构思维的转变。
常见Redis缓存策略对比分析
缓存策略的选择直接影响系统表现。Cache-Aside模式最常用,应用代码显式读写缓存,控制权完全在开发者手中。这种模式简单直观,但需要处理缓存与数据库的一致性问题。
Write-Through策略将写操作同时更新缓存和数据库。读操作总是命中缓存,保证了数据强一致性。代价是写入延迟略有增加,适合读多写少的场景。
Write-Behind模式更加激进,应用只更新缓存,由缓存异步批量更新数据库。这种策略写入性能最佳,但存在数据丢失风险。
Read-Through模式让缓存自己负责数据加载。缓存未命中时,缓存组件自动从数据库加载数据。这种模式简化了应用代码,但需要缓存组件支持。
每种策略都有其适用场景。没有绝对的最佳选择,只有最适合当前业务需求的方案。
Redis在Java应用中的集成优势
Java生态对Redis的支持相当成熟。Spring Data Redis提供了简洁的API,让Java开发者能够轻松集成Redis。配置几个Bean,注解几个方法,缓存功能就实现了。
Redis丰富的数据类型让它在Java应用中大放异彩。String存储简单键值,Hash存储对象,List实现队列,Set处理去重,Sorted Set做排行榜。这些数据结构原生支持,不需要额外的序列化反序列化。
我们曾经用Redis的Sorted Set实现了一个实时排行榜功能,代码量不到50行,性能却远超传统数据库方案。这种开发效率的提升,在快速迭代的项目中价值巨大。
内存存储特性让Redis的读写速度达到微秒级别。相比磁盘数据库的毫秒级响应,性能提升是数量级的。对于需要快速响应的应用场景,这种差异直接决定了用户体验。
Redis的持久化机制平衡了性能与数据安全。RDB快照适合备份,AOF日志保证数据安全。根据业务需求灵活配置,既享受内存速度,又不丢失重要数据。
集群模式下的Redis提供了高可用性。主从复制、哨兵模式、集群方案,不同规模的系统都能找到合适的部署方式。这种可扩展性让Redis能够伴随业务一起成长。
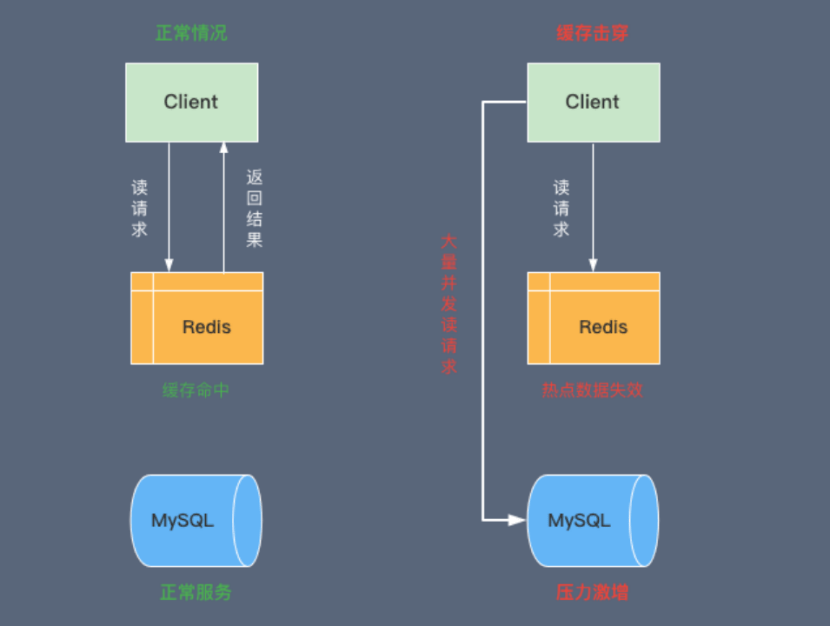
缓存就像给系统穿上防弹衣。但再好的装备也有弱点,缓存穿透、击穿、雪崩就是三个需要重点防御的漏洞。理解它们的区别,比记住解决方案更重要。
缓存穿透、击穿、雪崩问题对比与解决方案
缓存穿透像对着空气开枪——查询根本不存在的数据。恶意攻击者可能故意查询不存在的用户ID,导致每次请求都直达数据库。我们去年就遇到过这种情况,某个接口突然收到大量异常请求,数据库连接数瞬间爆满。
解决方案其实很巧妙。布隆过滤器能在内存中快速判断数据是否存在,把无效请求挡在数据库之外。另一种做法是缓存空值,给不存在的key设置短暂过期时间。虽然会占用少量内存,但保护了数据库这个核心资源。
缓存击穿则是热点数据突然失效的连锁反应。想象一下秒杀场景,某个热门商品缓存过期瞬间,成千上万的请求同时涌向数据库。这种“集体冲锋”很可能压垮数据库连接池。
解决击穿需要一些设计技巧。永不过期的热点数据配合异步更新是个稳妥方案。或者使用互斥锁,只允许一个线程重建缓存,其他线程等待。在Java中,用Redis的setnx命令就能实现简单的分布式锁。
缓存雪崩最危险,就像雪崩一样——大量缓存同时失效。可能是缓存服务器重启,或者设置了相同的过期时间。整个系统从高速缓存模式瞬间退化为原始数据库查询,这种落差足以让任何系统崩溃。
预防雪崩需要未雨绸缪。过期时间随机化能避免缓存集体失效。集群部署保证高可用,即使某个节点宕机也不影响服务。我们给关键业务数据设置了两层缓存,本地缓存加Redis缓存,相当于给系统上了双保险。
不同业务场景下的缓存策略选择
用户会话管理适合简单的键值存储。设置合理过期时间,既保证用户体验又避免内存浪费。我记得有个社交应用最初将会话缓存设为一周,后来发现大部分用户其实只会活跃几小时。
商品详情页的缓存需要更精细的设计。不同商品的热度差异很大,热门商品应该缓存更久。我们采用分层策略:爆款商品永不过期,普通商品缓存一天,冷门商品直接查询数据库。
购物车场景比较特殊。数据更新频繁但实时性要求不高,适合Write-Behind模式。用户添加商品时先更新Redis,然后异步同步到数据库。即使同步延迟几分钟,用户通常也能接受。
消息队列用Redis的List结构实现简单又高效。我们曾经用lpush和brpop替代了专业的消息中间件,在业务初期节省了大量运维成本。当然业务量上来后还是迁移到了专业队列,但Redis在原型阶段的快速验证价值无可替代。
排行榜是Redis的经典应用场景。Sorted Set的天然排序特性让开发变得异常简单。只需要zadd和zrange两个命令,就能实现复杂的排名逻辑。这个设计确实非常巧妙,极大地减少了开发工作量。
Redis缓存性能优化与监控实践
内存优化要从数据结构入手。同样存储用户信息,String类型可能占用100字节,Hash类型可能只需要60字节。这种细微差别在数据量达到百万级别时,会演变成巨大的内存差距。
批量操作能显著提升性能。一次mget获取多个key,比循环get效率高得多。管道技术更进一步,将多个命令打包发送,减少网络往返次数。在需要大量读写操作的场景,性能提升可能达到10倍以上。
监控是保证缓存健康的眼睛。慢查询日志能发现潜在的性能瓶颈。我们设置了一个监控看板,实时显示缓存命中率、内存使用率、命令统计等关键指标。当命中率低于90%时,系统会自动发送告警。
键值设计也影响性能。太长的key浪费内存,太短的key可读性差。我们采用统一的命名规范:业务名:对象类型:ID。比如user:session:12345,清晰又简洁。
连接管理经常被忽视。连接池大小设置不当会导致性能问题。过小会限制并发,过大会消耗过多资源。根据实际负载动态调整连接数,这个经验是我们交了学费才学到的。
数据过期策略需要精心设计。volatile-lru淘汰最近最少使用的过期键,allkeys-lru淘汰所有键中的最近最少使用。选择哪种策略取决于业务特性。我们的做法是:缓存数据用volatile-lru,存储数据用allkeys-lru。
持久化配置平衡了性能与安全。RDB快照适合备份,AOF保证数据安全。在数据安全要求高的场景,我们采用AOF每秒同步。对性能要求更高的场景,使用RDB定时备份。这种灵活配置让Redis能适应各种业务需求。