1.1 什么是Hystrix及其在微服务架构中的作用
微服务架构把单体应用拆分成多个独立服务。服务之间通过网络调用相互协作。这种分布式特性带来了新的挑战——某个服务出现故障时,调用链可能像多米诺骨牌一样接连失效。
Hystrix正是为解决这类问题而生。它是Netflix开源的容错库,后来成为SpringCloud生态的重要组件。想象一下交通系统中的红绿灯和应急通道,Hystrix在微服务网络中扮演着类似的角色。当某个服务出现异常,它能及时阻断故障传播,为系统提供保护机制。
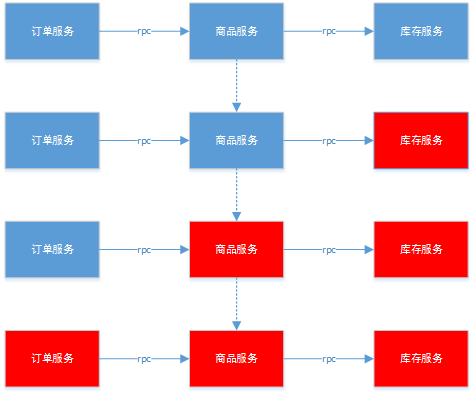
我记得有个电商项目,商品服务调用库存服务时经常超时。没有Hystrix的情况下,整个商品详情页都会卡住。引入Hystrix后,即使库存服务不可用,用户依然能看到商品基本信息,只是库存显示“暂时无法获取”。这种体验上的平滑过渡,正是Hystrix价值的体现。
1.2 Hystrix的核心功能:熔断、降级、隔离
熔断机制类似于电路保险丝。当服务调用失败率达到阈值,熔断器会自动打开。后续请求直接快速失败,不再访问故障服务。这避免了资源持续消耗在不可用的服务上。
服务降级提供备选方案。主服务不可用时,系统自动切换到预设的降级逻辑。比如支付服务调用失败,可以降级为记录支付请求,后续人工处理。这种设计哲学很实用——有总比没有好,差一些的体验远胜于完全不可用。
资源隔离通过线程池或信号量实现。不同服务调用使用独立资源,避免某个慢服务拖垮整个系统。就像船舶的水密舱室,一个舱室进水不会导致整艘船沉没。
这三个功能共同构建了系统的弹性。它们让微服务架构从“脆弱”变得“坚韧”,能够优雅地应对部分故障。
1.3 Hystrix与其他SpringCloud组件的集成关系
Hystrix不是孤立工作的。它与SpringCloud生态中的其他组件紧密配合,形成完整的微服务解决方案。
与Eureka的集成很有意思。服务消费者从Eureka获取服务列表,Hystrix为这些调用提供保护。当Eureka标记某个服务实例不可用,Hystrix会快速感知并调整策略。
Feign客户端天然支持Hystrix。只需简单配置,所有Feign接口都具备熔断能力。这种无缝集成大大降低了使用门槛。
Ribbon负载均衡器与Hystrix的配合也很默契。Ribbon负责选择服务实例,Hystrix保障调用过程的稳定性。它们就像接力赛跑的选手,各司其职又紧密协作。
配置中心ConfigServer为Hystrix提供动态参数调整能力。不需要重启服务就能修改熔断阈值,这个特性在生产环境中特别实用。
微服务架构就像交响乐团,每个组件都是乐手。Hystrix是指挥家手中的节拍器,确保整个演出不会因为某个乐手的失误而彻底混乱。
2.1 熔断器的工作原理与状态转换
熔断器的设计灵感来自电路保护。当电流过载时,保险丝熔断切断电路。Hystrix熔断器在微服务调用中实现类似功能。
熔断器有三种状态:关闭、打开、半开。初始状态为关闭,请求正常通过。当失败率超过阈值,熔断器跳闸进入打开状态。此时所有请求直接失败,不再尝试调用故障服务。经过设定的时间窗口,熔断器尝试进入半开状态,允许少量测试请求通过。如果这些请求成功,熔断器恢复关闭状态;如果继续失败,则保持打开状态。
这个状态转换过程很精妙。我记得一个物流系统的案例,地址解析服务偶尔响应缓慢。熔断器在检测到连续超时后自动打开,避免了整个订单处理链路的阻塞。大约10秒后,系统尝试发送一个测试请求,确认服务恢复后立即关闭熔断。整个过程完全自动,无需人工干预。
熔断器的智能之处在于它的自愈能力。不像简单的超时机制,它通过状态转换实现了故障服务的渐进式恢复。这种设计既保护了系统,又给了故障服务恢复的机会。
2.2 熔断器关键参数配置详解
配置熔断器需要理解几个核心参数,它们共同决定了熔断器的敏感度和恢复速度。
circuitBreaker.requestVolumeThreshold 设置滑动窗口内的最小请求数。只有当请求数量达到这个阈值,熔断器才开始计算失败率。这个设计避免了在低流量时期过早触发熔断。通常设置为20,意味着需要至少20个请求才能启动熔断判断。
circuitBreaker.errorThresholdPercentage 定义触发熔断的失败百分比。默认50%的失败率就会打开熔断器。这个值需要根据具体业务调整。对支付这类关键服务,可能需要设置更低的阈值;而对于非核心服务,可以适当放宽。
circuitBreaker.sleepWindowInMilliseconds 控制熔断器打开后进入半开状态的时间窗口。默认5000毫秒,即5秒后会尝试放行一个请求测试服务是否恢复。时间太短可能给尚未恢复的服务造成压力,太长则影响用户体验。
metrics.rollingStats.timeInMilliseconds 设置统计时间窗口长度。默认10000毫秒,即基于最近10秒的请求数据计算失败率。这个窗口大小直接影响熔断器的响应速度。
配置这些参数需要平衡。过于敏感的熔断会导致正常服务被误伤,过于迟钝又失去了保护意义。实践中,我们通常从默认值开始,根据监控数据逐步优化。
2.3 熔断器的监控与指标收集
没有监控的熔断器就像没有仪表盘的汽车——你只知道它在运行,但不知道运行状态如何。Hystrix提供了丰富的指标收集机制。
每个熔断器都维护着一组关键指标:请求总数、成功数、失败数、超时数、被拒绝数。这些指标通过滑动时间窗口统计,确保数据的时效性。指标收集的频率和精度可以通过配置调整,平衡监控开销和数据准确性。
Hystrix Metrics Stream以事件流的形式实时输出这些指标。任何支持Server-Sent Events的客户端都能订阅这个流,实现实时监控。我曾经搭建过一个简单的监控面板,通过订阅这个流,团队能直观看到各个服务的健康状态。
指标数据还能集成到现有的监控系统中。比如推送到Prometheus,通过Grafana展示。这种集成让运维团队能在统一的平台上查看整个系统的熔断状态。
监控的价值不仅在于发现问题,更在于优化系统。通过分析熔断器的触发记录,我们能识别出系统的薄弱环节。某个服务频繁熔断可能意味着需要扩容,或者代码逻辑需要优化。这些数据为架构演进提供了重要依据。
熔断器的监控数据就像系统的体检报告,定期查看能帮助我们提前发现潜在问题,避免小故障演变成大事故。 @Service public class UserService {
@HystrixCommand(fallbackMethod = "getDefaultUserInfo")
public UserInfo getUserInfo(String userId) {
// 调用可能失败的用户服务
return userClient.getUserInfo(userId);
}
public UserInfo getDefaultUserInfo(String userId) {
// 返回默认用户信息
return new UserInfo("default", "默认用户");
}
}
Java优学网SpringCloud负载均衡教程:轻松掌握微服务流量分发,告别系统崩溃烦恼
Java优学网SpringCloud服务熔断解析:轻松掌握微服务故障隔离,告别系统崩溃烦恼
Java优学网SpringCloud Ribbon讲解:轻松掌握微服务负载均衡,提升系统性能与稳定性
Java优学网异常处理入门解析:轻松掌握程序错误应对技巧,告别崩溃烦恼
零基础学Java优学网try-catch课:轻松掌握异常处理,告别程序崩溃烦恼
Java优学网Spring IoC讲解:轻松掌握控制反转与依赖注入,告别代码耦合烦恼